
...making Linux just a little more fun!
Amit Kumar Saha [amitsaha.in at gmail.com]
Hi all,
The latest issue (http://linuxgazette.net/139/index.html) of LG has a new feature - a "Digg this!" button (as you must have noticed it). I am looking after this sub-project. I would like to get some feedback about this as to how to improve it; or any modifications /suggestions.
Cheers,
-- Amit Kumar Saha [URL]:http://amitsaha.in.googlepages.com
Peter Holm [peter.g.holm at gmail.com]
I have searched the net (google, newsgroups ...) to find an answer to this question .- but without success.
In KDE (for example) you can get individual desktops backgrounds for each virtual desktop. Well - i am used to a utility for M$-Windows called Xdesk that also can set the the desktops to have individual icons / folders.
I know that in the windows world they change a regkey that tells where the desktop belongs for each switch so such a 'true virtual desktop'
I have also in M$-Windows created bathc-files to use with less intelligence window-managers, theese batch-files separately update the regkey to get my own way to create 'true virtual desktops'
Is there any program that i can get to have different desktops-folders or is there any way to trick either kde / gnomw / idesk to have different desktops?
I suppose it should go with renaming the main folders there they save the desktop-information for each switch, so the desktop you are on have specific icons and settings, and then force kde /gnome / idesk / whatever to update.
And yes - i know that the folder layout differs for Kde / Gnome / Idesk / Whatever - i am satisfied with a solution that fits one of theese or maybe someother Desktop Manager (for example XFCE4)
sorry for the length of the letter - feel free to strip out whatever you like to make it place in the list.
-- Best Regards /Peter
Ben Okopnik [ben at linuxgazette.net]
----- Forwarded message from "Martin A. Totusek" <bb553@scn.org> -----
Date: Wed, 20 Jun 2007 19:53:09 -0700 From: "Martin A. Totusek" <bb553@scn.org> Reply-To: "Martin A. Totusek" <bb553@scn.org> To: Ron Jenkins <rjenkins@unicom.net> CC: "Marjorie L. Richardson" <gazette@linuxgazette.net> Subject: Re: MI/X PPC Classic Macintosh X Window server (freeware)Looking for:
MI/X PPC Classic Macintosh X Window server (freeware) MicroImages, Inc. (21 October 1998)
NO LONGER POSTED ONLINE by MicroImages - I wish to find a copy to use and to archive
- Martin A. Totusek
------------
MI/X for Macintosh A Professional, Free X Server.
Mac computers run the TNT products http://www.microimages.com/index.htm through the unique MicroImages X Server (MI/X), which MicroImages supplies with every TNT product for Macintosh.
MicroImages is also pleased to make this X Server freely available for Macintosh users who do not have any of the TNT products. You may want to use your Power Macs as X terminals in a network environment -- MI/X works fine as an X terminal emulator. You may also want to make your PC a true X Server and run multiple X clients from your desktop. MI/X works fine there, too -- after all, that's why MicroImages developed MI/X in the first place.
If you can configure a telnet session, you know enough to use MI/X. Since MI/X for the Macintosh is made freely available, MicroImages cannot respond to individual user requests for technical support. However, MicroImages maintains MI/X as the X Server for its line of TNT professional products http://www.microimages.com/index.htm, so you will find MI/X a stable and robust performer.
If you have any questions comments or suggestions regarding MI/X for Macintosh contact us at mix@microimages.com
User Reviews
A free X Window server for Power Macs. It's got all the requisite features - host allow/deny, background configurability, etc. - and comes with twm, although you can use any other window manager.
"Although it was not as easy to configure as come commercial X server software, I was connecting to our UNIX server relatively effortlessly. It's a great tool to have in our computer lab to connect to the workstation for one of our research projects." - Jiro Fujita
"This is an amazing piece of software - especially considering the price. MI/X performs well on my 7200/90 and is very much easier to set up and use than MacX or its reincarnation, Xoftware. I noted a few minor bugs with screen redrawing when using the backing store but on first impression this seems to be a useful and usable X-server." - David Robertson, Programmer, Department of Computer Science, University of Otago
[ ... ]
[ Thread continues here (1 message/3.62kB) ]
Smile Maker [britto_can at yahoo.com]
Folks,
Here is my scenario,
We have a version control repository running on my end and we have the branch offices too.Now people are checking in and out tunneling through firewall to the version control server in my end.
Now my problem is remote users are experiencing slow process when they are doing version control transactions.
We thought of rsyncing the repo to the remote machine.and the users can do the version control operations locally but how do we maintain the consistency of files in all offices ?
Thanks & regards, Britto
[ Thread continues here (3 messages/4.07kB) ]
Smile Maker [britto_can at yahoo.com]
Folks,
Suggest me one good mass mailer program for linux ( So i am looking for free).
The project i found in sourceforge was not helpful for me.
-- Britto
[ Thread continues here (3 messages/4.96kB) ]
Rick Moen [rick at linuxmafia.com]
There's an interesting ongoing trend among hardware manufacturers, to incorporate more and more low-end RAID functionality into either core motherboard circuitry or cheap add-on cards. Unfortunately, the resulting RAID functions tend to be slow and buggy compared to Linux "md" driver software RAID. Caveat emptor.
----- Forwarded message from Rick Moen <rick@linuxmafia.com> -----
Date: Wed, 20 Jun 2007 13:35:10 -0700 From: Rick Moen <rick@linuxmafia.com> To: Pekka Hellen <pekka@hellen.fi> Subject: Re: FakeraidQuoting Pekka Hellen (pekka@hellen.fi):
> Im wondering that what is the situation with Silicon Image 4723, is that > fakeraid or not?> > btw great list you have there > http://linuxmafia.com/faq/Hardware/sata.html#fakeraid > > Best regards > Pekka Hell�n > Finland > **
The 4723 appears to be genuine hardware RAID (albeit for RAID0 or RAID1 only), and is implemented as a port multiplier and RAID controller add-on, that attaches to a SATA port, which is then for some reason referred to as the "EZ-Backup" port, to which you can connect two SATA drives. Unfortunately, reports I hear suggest that it has very bad performance.
My apologies for being a bit behind on maintenance of my SATA on Linux page. I've been away on vacation, and am just now returned.
----- End forwarded message -----
Ben Okopnik [ben at linuxgazette.net]
----- Forwarded message from "s. keeling" <keeling@spots.ab.ca> -----
Date: Sat, 2 Jun 2007 19:25:54 -0600 From: "s. keeling" <keeling@spots.ab.ca> To: ben@linuxgazette.net Subject: Domain name registrar follies.Hey Ben. Que pasa? Apologies in advance, as I know this rambles quite a bit. I learned some important lessons from it, so thought I'd pass them on.
I ran into a bit of (for me, anyway) an interesting mystery today, and it partly concerns LG's very own Rick Moen. I was reminded while brousing through /current that I'd been meaning to go look into a few things on Rick's Linux Mafia site (I'm presently in the last stages of recovering from a failed hard drive[ii], and old bookmarks is about all that's left to do).
So, Iceweasel --> linuxmafia.net ...
Yup, that was my first mistake. Rick's not at .net, he's at .com. I don't know how I came up with .net (creeping senility perhaps), but there you are. BTW, linuxmafia.net appears to be a P2P invite only torrent site out of Georgia, as one of my mailinglist buddies was kind enough to point out. He followed that up with "whois is your friend."
Well, I knew that. On the other hand, it's not always your (or my, at least) friend because "whois -h whois.arin.net linuxmafia.com" shows no match. On the other hand, "dig mx" does work. Um, wtf? Is there some serious Juju going on here, or am I just more ignorant than I hope I am?
The plot thickens; I'm not the only one. F-Secure appears to be a bit confused on this sort of thing too. see:
http://www.f-secure.com/weblog/#00001203So, what's wrong with whois, or is there something magical going on about Rick's (and F-Secure's example) sites? Or, am I an idiot?
I was getting too cute with shell aliases[i], but I see plain old "whois linuxmafia.com" does work quite nicely, showing it's registered with Tucows Inc. I thought my "arin" alias was all I needed to find registry info in this part of the world, "ripe" for Europe, "apnic" for the Far East, and etc. Definitely not true. Drat.
The moral of the story appears to be that (as a plain "whois $BLAH" shows):
Domain names in the .com and .net domains can now be
registered with many different competing registrars.
Go to http://www.internic.net for detailed information.
So, I ought to be giving up on my ("my friend") whois aliases.
--------------------------------------
On the off-chance you end up dumping this into LG's "Mailbag", I'll add that anyone who hasn't spent time at Rick's site is missing some great stuff. I've learned a lot from him over the years, and his wry, dry, diplomatic, and often truly vitriolic BOFH "we don't suffer fools here!" style is damned entertaining.
And for Rick, guess what? linuxone.com is still registered, at Computer Services Langenbach Gmbh DBA joker.com. DN squatter snapped it up I guess, since it mentions none of the entities you mention in your article.
[ ... ]
[ Thread continues here (4 messages/11.48kB) ]
Neil Youngman [ny at youngman.org.uk]
Occasionally I get a window behaving in a way I haven't seen until recently. The window is not displayed, just the title bar. When I move the cursor over the title bar the rest of the window displays, but when the cursor is moved off the window it shrinks back to just the title bar.
I assume that this is configurable behaviour in some way, but it seems to happen fairly randomly. It's most common in JBuilder (spit), but it's also happening to an xterm window at the moment.
The Window Manager is KDE and I'm running Debian Etch. Does anyone know what causes this and how to stop it?
Neil
[ Thread continues here (3 messages/3.94kB) ]
Rick Moen [rick at linuxmafia.com]
This is just out: OSI President Tiemann has made a ringing statement that badgeware licensing is absolutely not open source, and has called upon the community to support him. We of course should do so, unequivocably.
----- Forwarded message from Michael Tiemann <tiemann@opensource.org> -----
Date: Wed, 20 Jun 2007 20:46:56 -0400 From: Michael Tiemann <tiemann@opensource.org> To: license-discuss@opensource.org Subject: when is an open source license open source?Today I read a blog posting from Dana Blankenhorn (http://blogs.zdnet.com/open-source/?p=1123) that has compelled me to respond. I may well be preaching to the choir on this list, but the blog posting I wrote in response (http://opensource.org/node/163) is a request for the choir to now sing as one. If I am asking you to do something you do not agree with, I'm sure you'll let me know. If you do agree, now is the time to be heard. Thanks!
M
----- End forwarded message -----
[ Thread continues here (2 messages/2.06kB) ]
[nilesh.04 at lnmiit.ac.in]
hello sir,
my password is 100bits long so i put that in a text file now i have to encrypt n decrypt by data with in file.
pls reply me as soon as possible ,hoping positive responds from your side
[ Thread continues here (5 messages/2.95kB) ]
Rick Moen [rick at linuxmafia.com]
[Forwarding Ben's private mail, with commentary, at his invitation.]
As a reminder, Centric CRM, Inc. has recently been one of the most problematic of the ASP/Web firms abusing the term "open source" for their products, in part because their flagship product (Centric CRM) has been notorious during most of this past year as the most clearly and unambiguously proprietary software to be offered with the ongoing public claim of being "open source".
I'd call this (below-cited) PR campaign blitz -- apparently, they're intensively hitting reporters known to be following this matter -- really good news, though it has to be read attentively:
o Former OSI General Counsel Larry Rosen's "OSL 3.0" licence is a really good, excellently designed, genuine copyleft licence that is especially well suited for ASP use, because it's one of the very few that have a clause enforcing copyleft concepts within the otherwise problematic ASP market. (In ASP deployments, there is ordinarily no distribution of the code, so the copyleft provisions of most copyleft licences such as GPLv2 have no traction, and are toothless.) Also, as Centric CRM, Inc. is keen to point out, OSL 3.0 is an OSI-certified open source licence.
o At the same time, the careful observer will note that this announcement concerns the product "Centric Team Elements v. 0.9", which is not (yet?) the firm's flagship product. That flagship product remains the entirely separate -- and very, very clearly proprietary, product "Centric CRM v. 4.1", which one wryly notices has been carefully omitted completely from this communique.
Just in case there is any doubt about Centric CRM 4.1's proprietary status, here's one key quotation from the product brochure, about the applicable licence, "Centric Public Licence (CRM)": "The major restriction is that users may not redistribute the the Centric CRM source code."
Now, it may be that the Centric CRM product is on the way out, and that Centric Team Elements (with genuine open source licence) will be taking its place. Or maybe not. Either way:
The bad news, but perhaps not too bad, is that Centric CRM, Inc. has spent this past year to date falsely and misleadingly claiming that its product line is open source -- and deflecting critics by claiming that the term "open source" is (paraphrasing) subject to redefinition and needn't be limited to what OSI (inventer of that term in the software context, and standard body) defines it to be. That misleading and deceptive language is still very much a prominent part of the company's pronouncements to this day, remains on the Web site, and doesn't seem to be disappearing.
The good news is that the firm appears to be sensitive to the public relations problem it created for itself, and may be taking steps to fix it.
----- Forwarded message from Ben Okopnik <ben@linuxgazette.net> -----
[ ... ]
[ Thread continues here (1 message/16.78kB) ]
Thomas Adam [thomas.adam22 at gmail.com]
Hello all --
This question is purely to test the water. I remember a good few
years ago now using a Sun workstation running some old version of
SunOS. One thing I remember about it clearly though is that it had a
cool keyboard with a whole set of keys down the far left-hand side
[1].
So I was wondering...
a) Is this keyboard standard? For instance, if I go looking for a "sun keyboard", I'm not going to encounter several different versions which work subtly different from one another, am I?
b) I've heard various rumours I'd need a sun <--> PC converter to use such a keyboard? Some websites say you need one, others don't even mention it. Some even say you build one, but I don't like the thought of this -- I'm a software engineer for a reason; I hate hardware.
Using it under Linux (X11 specifically) wouldn't be much of a problem.
I hope...
-- Thomas Adam
[1] Looked like this one does: http://sunstuff.org/hardware/components/keyboards/sun.type4-keyboard.2.jpg
[ Thread continues here (10 messages/16.58kB) ]
Amit Kumar Saha [amitsaha.in at gmail.com]
Hi all,
I am trying to install Xen 3.1.0 from source. When I do a "make world", after some processing I get this
Cannot find linux-2.6.18.tar.bz2 in path .and it starts retrieving the file from www.kernel.org
I do not want this. I have got a local copy of linux-2.6.18.tar.bz2 in /usr/src as well as the directory where Xen source code is stored. PATH setting did not help either.
How can I get around this?
I did install Xen 3.0 from synaptic,but it did not seem to work either. It is not able to boot into the Xen kernel, because the file vmlinuz-xen-0 is not created at all.
Please suggest how I can get Xen up and running!
Thanks
-- Amit Kumar Saha [URL]:http://amitsaha.in.googlepages.com
[ Thread continues here (8 messages/11.81kB) ]
Amit Kumar Saha [amitsaha.in at gmail.com]
Hi all,
Keeping in mind the wide variety of domains, age-group and experience of TAG, I would be really interested to get some project proposals, specifications of which are mentioned below:
1. Duration - 6 Months
2. Domains related to : Network Security, Clusters, Embedded or Real Time Systems.
This is a final year project for me. So I am really looking forward to project work which is going to have some real-world value. Please note that the topics i have given are of my interest and ideas are welcome in other topics as well.
Cheers,
-- Amit Kumar Saha [URL]:http://amitsaha.in.googlepages.com
Smile Maker [britto_can at yahoo.com]
Folks:
I need to do the following stuff:
Find the particular string in a file and remove that line which has that particular string from the file , that should be done from the command line or from the script.
Thanx... Britto
[ Thread continues here (4 messages/1.86kB) ]
[ In reference to "Mailbag, Part 2" in LG#137 ]
Rick Moen [rick at linuxmafia.com]
Forwarding back to the list. Greetings from Istanbul.
----- Forwarded message from sindi keesan <keesan@sdf.lonestar.org> -----
Date: Sat, 9 Jun 2007 18:43:23 +0000 (UTC) From: sindi keesan <keesan@sdf.lonestar.org> To: Rick Moen <rick@linuxmafia.com>cc: karolisl@gmail.com
Subject: Re: [TAG] (forw) Re: (forw) Re: lpr works for user not root inBasiclinux 2.1
Sorry I do not have the last mail in this series. Please post this mail properly to TAG list members and wherever else it goes. I discovered our long email exchange is now on the web. Thanks.
The author of BasicLinux helped me to get eznet working properly for 'user'. He said eznet behaves properly (does not reset permissions on /dev/tty*) if you exit it (ppp-off) before rebooting. Otherwise it leaves permissions reset so only root can dial. (It might be safest to also chmod o+w /dev/ttyS1 in rc too for when user forgets to hang up).
I am finally ready to set up the latest version of Basiclinux (3.50 - with jwm window manager that can be used without a mouse) for use by 'user'.
61MB with libc5 (used in the original download to save space), glibc 2.2.5 so (added for Opera), links, links2, lynx, Opera 9.21, kermit, msmtp (SMTP authentication), base64 to encode attachments for msmtp, dropbear and scp, abiword, netpbm, gs-8.54, mplayer, sox, svgalib, svp (svgalib-based ps/pdf viewer), zgv, antiword, xlhtml, ppthtml, all added to the jwm menu, and everything that came in the original 2-FD download including Xvesa, jwm, mgp, xli, and pcmcia support but no compiler. 2.2.26 kernel so no USB-storage support unless you change to 2.4.31 kernel and modules.
To start vt1 in X: tty1::respawn:-/bin/sh -sc startx rather than changing runlevels.
What else might the novice linux user want? Someone's friend says their computer is too slow for the internet. I will make it run faster by adding linux.
Running Linux 2nd Edition (kernel 1.1) recommended 40MB for linux, or 250MB for a really large distribution. I could have done it in about 30MB by leaving out Opera and Abiword, which did not exist then.
Thanks to everyone on the TAG list for all the help and education.
Sindi Keesan
----- End forwarded message -----
[ In reference to "Booting Knoppix from a USB Pendrive via Floppy" in LG#116 ]
Ben Okopnik [ben at linuxgazette.net]
On Fri, May 25, 2007 at 12:45:17PM -0400, Jermaine wrote:
> Hey guys: > > I currently have a Toshiba Protégé M200 and I would love to play > around with a Linux LiveCD distro. This machine does not have an > internal floppy and or CD/DVD drive, however, it does have the > capability to boot off the internal SD slot by copying a floppy-disk > image (up to 2.88MB) to the SD card as long as you name it > $tosfd00.vfd. > > I know what you are thinking, but it'll never work... Think of it > this way, you can have a 2GB SD card but only 1.44 or 2.88MB worth of > that 2GB is usable, the rest of the space cannot be read under Linux. > To enable the ability to read the remaining space of the SD card, a > driver must be present for the Toshiba SD card reader under Linux. > The reason it'll never work is because Toshiba won't release > information regarding the device, therefore no driver. > > This brings me back to my original problem of getting a LiveCD to run > on my M200. I just happened to stumbled upon Ben Okopnik "Booting Knoppix > from a USB Pendrive via Floppy" article and I thought to myself "that > might be exactly what need." I read his entire article, but I am > still confused and don't know where to start. > > I saw the downloadable file version of the script, but what do I do > with it. Keep in mind I don't have a Linux machine or any prior Linux > experience.
Hi, Jermaine -
Well, that last bit is somewhat problematic - unless you can beg, borrow, or steal a Linux machine for a while, or have a friend with one who would be interested in helping you. Or, if you have access to a desktop machine (i.e., something which isn't going to give you the kind of problems that your Toshiba does), you could always boot Knoppix or some other distro on it and get yourself all set up.
The procedure itself, once you've taken care of the above, is fairly simple:
1) Download a Knoppix image [1] to your machine. 2) Download and run the script in the article; follow the prompts. 3) Copy the newly-created image to your flash device, as the last prompt says; however, in your case, try
dd if=boot.img of=/dev/sdb1/\$tosfd00.vfdinstead of the suggested location (this assumes that your flash drive is mounted as /dev/sdb, which is the common case.)
If the above doesn't work, feel free to ping TAG again - hopefully, with a list of all errors that you've seen (pasted and copied, please - no retyping!) and describing any non-text errors (i.e., "activity light on drive didn't come on" or whatever.)
I suspect that it should work out OK for you, since the problem these days is that the boot image is too big for the average floppy. However, since you have a 2.88MB allowance, this is likely to not be a problem...
Let us know how it works out for you!
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ In reference to "A Brief Introduction to IP Cop " in LG#125 ]
jessekemp [kempjw1 at sbcglobal.net]
I have setup IPCop and am seeing that I am taking errors (at about a 50% rate) any Idea how I can adjust the MTU rat which is currently set to 1500?
[ Thread continues here (4 messages/2.72kB) ]
Kat Tanaka Okopnik [kat at linuxgazette.net]
On Fri, Jun 22, 2007 at 04:57:02PM +0200, Emil Gorter wrote:
[[[ In a message addressed directly to me, entitled "very late addition to "Multipage tif file" in LG138" ]]]
Hi, Emil!
> I'm way behind on reading LG, so I saw your question from April only > today: > > http://linuxgazette.net/138/misc/lg/multipage_tif_file.html > > > It reminded me of a scanning/archiving assignment I got long time ago. > I don't remember when but I mailed LG about it before. > > I wanted to merge to separate TIFF pages (extracted from a 30+ page > scans using tiffsplit) into one PDF. It went like this:
tiffsplit?
Well, I just went off to install libtiff-tools, and tested tiffsplit on the file I'd been trying to open back then. No go, still.
TIFFReadDirectory: Warning, 552.tif: unknown field with tag 292 (0x124) encountered. 552.tif: Warning, incorrect count for field "DateTime" (19, expecting 20); tag ignored. Segmentation fault (core dumped)Looks like the original file was, as I thought at the time, exquisitely..."modified" to be "functional" in Wind0ws and borken elsewhere.
Ah well, thanks to that problem, I've acquired a suite of tiff tools. (Thank you for the nudge to add libtiff-tools to the arsenal.)
> tiffcp xaa.tif xab.tif combined.tiff > tiff2ps -2 -a combined.tiff | ps2pdf -sPAPERSIZE=a4 - > combined.pdf > > You'll get a high quality PDF that is much smaller than the TIFFs.
Nifty. It's pretty much the inverse (converse? reverse? obverse?) of the problem I was having, but it's nice to have the tip handy. Thanks!
-- Kat Tanaka Okopnik Linux Gazette Mailbag Editor kat@linuxgazette.net
Linux superstars, corporate heavyweights, and major customers all converged on the Mountain View Googleplex for the first of many Collaboration Summits. Hosted by the new Linux Foundation, the 3-day event focused on developer issues and, as Linux Foundation CEO Jim Zemlin stated, the sausage-making aspects of the open source ecosystem.
Although it started just after the announcement of Linspire partnering with Microsoft on multimedia support and patent IP (see below), conference organizers steered away from discussing the new Microsoft partnerships and potentially polarizing headlines. Instead, the focus was on working together on common goals. "They're projecting fear, uncertainty, and doubt. Let's come up with the things to move this platform ahead," Zemlin told attendees on the first day, which was open to journalists. After a public day with keynotes and press statements, the Collaboration Summit continued behind closed doors, and with blog silence.
The Linux Foundation hosted the Summit to bring together the diverse elements of the Linux community, and encourage face-to-face dialog. Among the aims behind the creation of the Linux Foundation was to foster innovation and act as a catalyst in the development of the open source software ecosystem. To some extent, the rapid acceptance of Linux and the diversity of projects has greatly enlarged what used to be a tight group of people, and better means of coordination and problem solving needs to be encouraged
Here's a link to the completed Summit schedule:
https://www.linux-foundation.org/en/Agenda_and_Schedule
The conference wiki is still bare, but here are a few of the Summit highlights:
Marc Shuttleworth (of Canonical and Ubuntu fame) praised the collaborative nature of the open source community and the tools developed to help coordinate work on OS projects, but said more work needed to be done to foster sharing and collaboration between existing projects and their respective communities.
"Collaboration is an easy term to say, but it's hard to do. We often don't know whom to talk to, upstream, so the question is: how can we make collaboration better?", Shuttleworth asked.
Later in his keynote, he emphasized the importance of getting timely patches out to Linux users. He also cautioned against viewing the differences between the open source community and the Microsoft world as a new Cold War. He said it was more about the underlying ideas than about the personalities and companies. [What was the term from the 1960s? "Peaceful Co-existence"?]
Some discussion continued on the third version of the GPL. The attending kernel developers were reported to be polite but unswerving in their desire to continue with GPL v2. The consensus seemed to be to wait, and see how adoption of GPL v3 goes in the application space, first.
Brian Aker, Director of Architecture at MySQL, led a discussion on issues with implementation of Linux threads that had users reverting to earlier kernel versions (or even switching to versions of Solaris). This also touched on issues with variation between distros.
Efforts were also coordinated for better device drivers, especially printer drivers. LF announced a new LSB driver development kit at the Summit. According Zemlin, "The LSB print driver development kit is exactly the kind of work we can expedite as a united community of developers, vendors, and users. We all know we have to make it extremely easy for printing manufacturers to target Linux. This kit will reduce the effort it takes for them to take advantage of the tremendous opportunity Linux represents, and will help users 'just print' while using the Linux desktop and printer of their choice."
There was also recognition that, with the open-sourcing of many development tools, toolmakers are reluctant to invest in frameworks and integration tools that match the utility and sophistication of Microsoft's Visual Studio suite. Eclipse goes part of the distance, but has to accommodate multiple developer needs and overlapping development models. Developers and ISVs have too many choices and too few standards.
Here is a small PDF showing Google's wish list of development
enhancements:
https://www.linux-foundation.org/images/f/fd/Dam4-google-santa-monica.pdf
http://www.informationweek.com/shared/printableArticle.jhtml?articleID=199904052
http://www.linux-watch.com/news/NS1996530724.html
Canonical Ltd., the commercial sponsor of Ubuntu, announced more details on Ubuntu Mobile and Embedded Edition, at Computex 2007 in Taipei. Following discussions at the Ubuntu Developer Summit in Seville, Spain, and a great response from its developer community generally, the target specifications and technical milestones for the project have been agreed. (With recent patches that support real-time processing in the kernel, some 50-60% of new mobile phones will be based on embedded Linux.)
Ubuntu Mobile and Embedded Edition will provide a rich Internet experience for users of Intel's 2008 Mobile Internet Device (MID) platform. To achieve this, Ubuntu Mobile and Embedded will run video, support sound, and offer fast and rich browsing experiences to the MID target user. Optimized for MIDs based on Intel's low power processors and chipsets, Ubuntu Mobile and Embedded edition is expected to deliver fast boot and resume times, and reside in a small memory and disk footprint.
"We are delighted with the progress of the Ubuntu Mobile and Embedded Edition", commented Jane Silber, Director of Operations at Canonical. "We have had a great response to our first announcement, with many developers showing interest in the project. With a clear roadmap, an active developer community, and a date for release, we look forward to bringing Ubuntu to Mobile Internet Devices."
The first full release of the software will be available in October 2007. Working collaboratively with Intel, Canonical is working to deliver software on actual devices in 2008.
(While this is, independently, good for Ubuntu and many mobile developers, large companies and ISPs continue to be concerned about the large number of Linux mobility platforms and lack of overarching standards. This is being noted increasingly at analyst events, and by companies such as Gartner and the 451 Group.)
Over 10,000 Web sites have been compromised by the "Mpack" hacker kit, and upwards of 100,000 user systems have had malware installed. The majority of compromised Web sites are in Italy, but the US has the third highest number of infected Web sites.
The multiexploit "Mpack" is a Russian collection of PHP script exploits that also collects statistics on the individual exploits. The hacked sites usually have additional IFRAME code embedded within the HTML source code, referencing the exploit server. Users are redirected to Web pages that download keyloggers, and other malware and exploits are selected based on the user's OS and browser.
Details on Mpack and its management console are reported at the
Websense and Symantec Web sites:
http://www.websense.com/securitylabs/alerts/alert.php?AlertID=782
http://www.symantec.com/enterprise/security_response/weblog/2007/05/mpack_packed_full_of_badness.html
http://www.symantec.com/enterprise/security_response/weblog/upload/2007/06/Italy%20pic2.html
In the same timeframe, US Senator Mark Pryor (D-Arkansas) recently
introduced legislation making it a crime to install spyware on systems
without users' consent. Called The Counter Spy Act of 2007, it gives
enforcement power to the Federal Trade Commission (FTC). Violators
could face both fines and prison.
http://pryor.senate.gov/newsroom/details.cfm?id=276980
Fulfilling its promise to the world last year, Sun is releasing a fully buildable implementation of the JDK to the new OpenJDK community. In front of a cheering developer audience at May's JavaOne, Sun's CEO Jonathon Schwartz announced the OpenJDK project, which will be tasked with implementing future releases of Java.
The project was seeded with Sun's May 6th JDK source bundle, which includes 25,169 source files. Almost all of the JDK - 6.5 million lines of code - is now available under the GPL, making it one of the largest contributions to the free software community in history. Of these, 4% or 894 cannot be shipped in source form: there are no rights for Sun to release the files, currently. An additional 1,885 files (8%) are not under GPLv2: These are mostly Apache-derived code, according to Sun.
Most of this exception code includes font and graphics rasterizers, sound engine code, and some crypto algorithms. There is also a little SNMP code, and some code for the Imaging APIs. (Richard Stallman of the Free Software Foundation has subsequently written that FOSSw developers should focus on this small subset of the JDK, and set Java completely free.) The encumbered code for the current JDK resides in the ALT_CLOSED_JDK, mostly in binaries. These are fully redistributable.
To help develop the community around OpenJDK, Sun launched a developer Web site: http://openjdk.java.net/
The site allows developers to download a full source-code bundle, or use Subversion to check out the code from the repository. Developers can contribute a patch to fix a bug, enhance an existing component, or define a new feature. Beside on-going blogs, the site also has links to live conversation via IRC on irc.oftc.net (#openjdk).
On the OpenJDK Web site, the founding engineers write: "With the community's help, we hope that encumbered code can be re-implemented over the next 6 to 12 months, balancing this critical engineering task with other priorities, and depending on the level of community participation in speeding this effort."
See FAQ at http://www.sun.com/software/opensource/java/faq.jsp.
Also: Sun announced a one-year roadmap for the OpenJDK initiative, including clearing the remaining encumbrances, open-sourcing an implementation of Java SE 6 and associated deployment code, implementation of the compatibility testing and branding program, and establishment of the governance and contribution model for the community. At JavaOne, Sun announced the formation of the OpenJDK Interim Governance Board, with the charter to write and gain ratification for a constitution for the OpenJDK Community, based on transparency and an open, meritocratic process. Initially, this is viewed as separate from the Java Community Process (JCP), where specifications are thrashed out, mostly with vendor input.
As part of the NetBeans 6 preview release, Sun has created pre-built Netbeans projects to make it easy and intuitive to dive into the OpenJDK code base.
[with major contributions from LG copy editor Rick Moen]
Microsoft ignited a firestorm of controversy in the open source community, when its lawyers used the medium of a Fortune magazine article to specify an exact number of (alleged) MS patent infringements in Linux and other FOSSw. The count was 235, including 42 violations for the kernel.
"Microsoft General Counsel Brad Smith and licensing chief Horacio Gutierrez sat down with Fortune recently to map out their strategy for getting FOSSw users to pay royalties."
It may be that Microsoft is creating FUD to slow the increasing speed of adoption of FOSSw at major corporations and many governments worldwide -- all current and former MS clients. It may be that MS sees the recent Supreme Court decision on software patents as weakening the value of its own patent portfolio, and thus needs to act quickly to maximize its advantage. Either way, the patent showdown will probably get worse, over the next few months. Microsoft expects royalties or cross-licensing deals, and maybe renewed customer loyalty. That seems to be the bottom line.
Microsoft has been asserting its patents recently, and has received royalty payments from Novell and other companies like Samsung. To prevent this trend, on March 28, the Free Software Foundation made public a revised GPLv3 draft. That may have set the stage for a confrontation with Microsoft, and perhaps between Microsoft and companies championing open source, like IBM and Sun.
For an alternative take, several Groklaw commentators have pointed out that:
Microsoft may have torpedoed their own case in advance by shipping a vast number of the usual GPLed and other open source codebases as part of Microsoft Services for Unix (nee Interix), creating a defence of equitable estoppel.
They will also face the defence of "laches" (impermissible delay), which becomes a bigger bar to litigation with each day that passes since both the Fortune magazine piece and their shipment of Interix.
If Microsoft ever sues anyone for patent infringement concerning a GPLed codebase, then both Microsoft (i.e., Interix) and patent-licensee Novell will immediately lose the right to distribute that codebase, per GPLv2 clause 7.
Complicating the already volatile situation, Dell became the first major systems provider to join the business collaboration that was formed by Microsoft and Novell for intellectual property (IP) assurance. As part of the agreement, Dell will purchase SUSE Linux Enterprise Server certificates from Microsoft, and establish a services and marketing program to migrate existing Linux users who are not Dell Linux customers to SUSE Linux Enterprise Server. Under this extended agreement, Dell will establish a customer marketing team for migrating Linux users who are not Dell Linux customers to SUSE Linux Enterprise Server.
"We're focused on delivering solutions that help simplify customers IT operations," said Rick Becker, vice-president of solutions at Dell Product Group. "Our customers have told us they want interoperability, and expect technology vendors to work better together. Dell is the first major systems provider to align with Microsoft and Novell in this collaboration, and we intend to lead in this space. This move is a huge success for the industry and, more specifically, for customers who haven't purchased Linux through Dell and who want to migrate to SUSE Linux Enterprise Server for the IP assurance and interoperability benefits."
From our editor Rick Moen, commenting via the Linux Users of Victoria mailing list:
"The Fortune piece that set off the patent debate contains embarrassing factual gaffes such as this one:
Lawyers for the Free Software Foundation have been able to force developers who incorporated free software into proprietary products to open up their source code, for instance."
"This is a notorious bit of misinformation often promoted by various opponents of copyleft licensing: In fact, copyright law provides no mechanism whatsoever to compel such a disclosure, and no such event has ever occurred (nor could it)."
Rick separately adds:
"You are advised to not hold your breath waiting for Microsoft Corp. to state patent numbers and clarify what specific open source / free-software codebases it believes are encumbered by its patents. For one thing, that would -- as you suggest -- enable anyone and everyone to assess those claims' merits. Also, it would assist open-source coders in, where necessary, rewriting their code with (probably) breathtaking speed to use other, equivalent techniques. The Redmondians know -- from watching the dismal fate of the few SCO infringement claims that SCO bothered to detail usefully -- that they cannot compete in a fair match of programming or analytical skill, so they instead make only vague claims that their better-staffed and more-energetic competition cannot address."
From Matt Asay, GM of Alfresco, who will be presenting at the Open Source Business Conference in late May: "If we could have referenced the MS 'patent threat' earlier [for our conference], it would have doubled our attendance, I'm sure."
"Microsoft Takes on the Free World"
http://money.cnn.com/magazines/fortune/fortune_archive/2007/05/28/100033867/
Also see: "Three Scenarios for How Microsoft's Open Source Threat
Could End"
http://www.informationweek.com/news/showArticle.jhtml?articleID=199602086
Ubuntu Live
July 22-24, 2007, Portland, Oregon
Security '07 / HotSec '07
August 6-10, Boston, MA
MetriCon 2.0, Workshop on Security Metrics
August 7, Boston, MA
Linux Kernel '07 Developers Summit
September 4-6, Cambridge, U.K.
RailsConf Europe 2007
September 17-19, Berlin, Germany
Storage Networking World
October 15-18, Dallas, Texas
The openSUSE community announced the fourth public alpha release of openSUSE 10.3. Highlights include the YaST meta packages handler; InstLux allows users to start the Linux installation from Windows; TeX Live replaces teTeX; first parts of KDE4svn entered Factory; OpenOffice.org 2.2; GNOME 2.18.1; improvements to the init script starter ('startpar') to reduce boot time; first changes to support Sony PS3; Linux 2.6.21 with an updated AppArmor patchset; initial support for installation in Afrikaans, Gurajati, Hindi, Marathi, Tamil, Xhosa, and Zulu."
Quick link to the DVD torrent files:
openSUSE-10.3-Alpha4-DVD-i386.iso
Mid-June also saw the release of kernel 2.6.22-rc5. Said Linus: "On a more serious note, I have to admit that I'm a bit unhappy with the pure volume of changes this late in the game. I was really wanting to stop some of the merges, but, while not all of it really fixed regressions, there really are a lot of bugfixes in there."
Among the updates in Fedora 7 are user installation tools that allow for several different "spins", which are variations of Fedora built from a specific set of software packages. Each spin can be a combination of software to meet requirements of specific end users. In addition to a very small boot.iso image for network installation, users have the following spin choices:
GNOME and KDE desktop environment-based bootable Live images that can be installed to a hard disk. These spins are meant for desktop users who prefer a single disk installation, and for sharing Fedora with friends, family, and event attendees.
A regular image for desktops, workstations, and server users. This spin provides a good upgrade path and similar environment for users of previous releases of Fedora.
A set of DVD images that includes all software available in the Fedora repository.
This release provides for enhanced wireless networking. The NetworkManager presents a graphical interface that allows user to quickly switch between wireless and wired networks for increased mobility. NetworkManager is installed by default in both GNOME and KDE Live CDs.
Additionally, Fedora Core 7 uses Python 2.5, and all of the Python
software available in the repository uses it.
http://docs.python.org/whatsnew/whatsnew25.html
Fedora 7 includes Liberation fonts, which are metric equivalents for several well-known proprietary fonts found throughout the Internet, and give better results when viewing and printing shared documents.
SUSE 10 SP1 is out now, and provides enhancements in the areas from the desktop to the data center, including:
Enhanced server virtualization and management enables unmodified Windows and Linux guest operating systems to run with near native performance.
Updated high availability storage infrastructure
Support for Open Enterprise Server 2 and paravirtualized NetWare.
Enhanced security features:
Novell AppArmor 2.0 security framework now includes support for Apache Tomcat.
Support for new processor technologies, including Quad-Core Intel Xeon and AMD Opteron processors.
On the desktop, SP1 delivers updates to the desktop effects engine, a re-designed main menu, and the ability to play embedded video in OpenOffice.org presentation files. It also provides improved integration with enterprise technologies such as Microsoft Active Directory and Microsoft Office, including the new OpenXML/ODF translator to convert Microsoft Word 2007 documents to OpenOffice.org. (That Novell-Microsoft patent deal, again!)
And... SUSE Linux 9.3 is now officially discontinued, and out of support.
See: http://www.novell.com/linux/sp1highlights.html
Skype Version 1.4.0.74 for Linux was released June 14. "The big news of this release is the support of glibc 2.3 systems. What this means is that Skype 1.4 will now run on some older systems without upgrading the base system."
Skype for Linux previously required glibc 2.3.3 or greater and Qt 3.2 or greater. If you do not have Qt 3.2 or greater, you are still able to use Skype for Linux by downloading its static version that has Qt 3.2 compiled in.
Besides substantial bugfixes, this update
includes Skype's own audio codec and an improved conference call
mixer.
http://www.skype.com/download/skype/linux/
As a present to its community, instead of releasing Bugzilla 2.24, the Bugzilla Project has released Bugzilla 3.0. Earlier development snapshots named 2.23.x have become the new Bugzilla 3.0. This is the first major upgrade to the popular tool in almost a decade. Among the Bugzilla changes are mod_perl support and a Web Services interface using the XML-RPC protocol.
Download the new Bugzilla here: http://ftp.mozilla.org/pub/mozilla.org/webtools/bugzilla-3.0.tar.gz
At the JavaOne conference in San Francisco, Robert Brewin, Sun's CTO of software, and NASA's Patrick Hogan showed off a new open-source geospatial browser plugin that implements Java GL and incorporates NASA's visualization technology. The new software also allows developers to create mashups and detailed geo-spatial simulations.
One demonstration was the DiSTI F-16 Flight Simulator, a Web plugin based on Java GL Studio. It allowed a user to 'fly' an F-16 with external and cockpit views, as it maneuvers over the Earth's terrain. A collaboration between Sun Microsystems, NASA Ames, and DiSTI, the simulator links Sun's Java Open GL platform, NASA's World Wind, which provides actual satellite imagery and radar topography from Shuttle missions, with GL Studio for Java - to enable Java developers to create 3D, real time visualizations of the Earth, using cost-effective, high fidelity imagery.
DiSTI's GL Studio package lets an instructional designer integrate photo-realistic objects into simulations that react just like the real parts. Such parts affect the performance of the systems, and accurately reproduce real behaviors (i.e., unscrew an important connector from a simulated jet engine, and it will stop running.)
The NASA World Wind Java SDK is platform independent, and current demos run under Fedora Core 6, Ubuntu, Microsoft Windows, and Mac OS X.
There were some problems with the World Wind download from NASA, but these seem to have been fixed by mid-May. Check out the FAQ on WorldWind Central: http://www.worldwindcentral.com/wiki/WWJava_FAQ
Primary Download Site : http://www.simulation.com/products/glstudio/content/JDJ/index.html
In May, at Red Hat Summit 2007 in SAN DIEGO, Red Hat announced the availability of Red Hat Exchange (RHX). RHX extends Red Hat's Open Source Architecture to include integrated business application solutions from fourteen open source partners built on Red Hat Enterprise Linux and JBoss platform software.
All solutions are purchased, delivered, and supported via a single, standardized Red Hat subscription agreement with consolidated billing covering the complete application stack. At the RHX Web site, customers have access to application profiles, user ratings and reviews, free trials, and online purchase options for all applications. Red Hat will provide customers with a single point of contact for all support issues throughout the application stack. In addition, RHX may be purchased through select Red Hat Value-Added Reseller Channel partners.
RHX launch partners include Alfresco, CentricCRM, Compiere, EnterpriseDB, Groundwork, Jaspersoft, Jive, MySQL, Pentaho, Scalix, SugarCRM, Zenoss, Zimbra, and Zmanda.
"When customers can minimize the number of number of vendors they are dealing with and the associated number of support contracts, they can reduce the complexity and often the cost associated with managing workloads," said Al Gillen, Research Vice President, System Software at IDC.
For more information about RHX, visit http://www.redhat.com/rhx and http://rhx.redhat.com.
At its Red Hat Summit, Red Hat announced a joint program with Intel to bring hardware-assisted virtualization to desktop PCs with Intel vPro technology. Using Intel vPro PCs, IT departments will be able to deploy appliances in a virtual machine that bring enterprise-class management and security to the PC.
"The legacy desktop falls short in its ability to provide a secure, reliable and manageable environment," said Brian Stevens, CTO at Red Hat. "Intel vPro technology combined with a Red Hat Virtual Appliance OS will allow customers to create a rock-solid foundation that can then provision, manage and secure the PC. This technology will reduce operational costs and increase operational flexibility."
The Appliance OS from Red Hat will support pluggable Virtual Appliances to deliver functions such as network security, provisioning, monitoring and asset management, regardless of the state of the desktop OS. In collaboration with Intel, Red Hat plans to develop, productize, and support software components, including the hypervisor, the Service OS, and the Software Development Kit (SDK).
Active development on the project is underway today, with beta software expected later this year and general release planned for 2008.
Linspire, Inc., developer of the Linspire commercial and Freespire community desktop Linux operating systems, and Parallels, Inc., maker of desktop virtualization solutions for Windows, Linux, and Mac OS X, have announced the Parallels Workstation 2.2 desktop virtualization solution for Linspire and Freespire users via CNR, a one-click delivery service for desktop Linux software. The companies also announced a technology partnership where Linspire will make a Freespire Virtual Appliance available using Parallels.
"Virtualization continues to impact the industry," said Randy Linnell, Vice-President of Business Development of Linspire. "We're excited about expanding our relationship with one of the leaders."
Parallels Workstation for Linux is a virtualization solution allowing Linux users to simultaneously run any version of Windows, including Windows Vista, any Linux distribution, Solaris, FreeBSD, NetBSD, OpenBSD, OS/2, eComStation, or DOS, in a stable, secure virtual machine on any Linux-powered PC. No re-booting or partitioning is required, and users never need to shut down or leave their home desktop to access a virtual machine.
Parallels Workstation is available immediately to Linspire and Freespire users for $49.99. Linspire and Freespire users can download and buy Parallels Workstation via CNR at http://www.linspire.com/parallels
FiveRuns, a vendor of enterprise-class management for Rails and other popular open source and commercial systems, has released RM-Manage, the first product from the FiveRuns Enterprise Management Suite for Rails.
The Management Suite for Rails will manage the full Rails application lifecycle, from automating the setup and maintenance of an integrated Rails development environment to ensuring Rails applications perform well in production. Following the release of the RM-Manage, RM-Install will ship in June. FiveRuns will complete the Management Suite for Rails with three additional products to help in the pre-production performance testing, deployment, and end-to-end visibility of Rails applications.
RM-Install, a free, multi-platform, enterprise-ready Rails stack, supports developing and deploying Rails applications without manually installing, configuring, or maintaining various integrated software components. RM-Install includes: a single integrated and tested Rails stack with pre-compiled binaries for Ruby, Rails, MySQL, Apache, Lighttpd and other important libraries, a stack management update component, and a demo application showing Rails and AJAX functions.
Data, the inquisitive and evolving robot of Star Trek NG, was among the four 2007 inductees announced for Carnegie Mellon University's Robot Hall of Fame.
The four inductees - the one-legged Raibert Hopper, the NavLab 5 self-steering vehicle, the LEGO(R) Mindstorms kit, and Data - were announced in May at the fourth annual RoboBusiness Conference in Boston. Some robots from the first three induction classes include the Mars Pathfinder Rover; Honda's ASIMO robot; the HAL 9000 computer from "2001: A Space Odyssey"; the "Star Wars" duo of R2-D2 and C-3PO; and Gort, the metallic giant from "The Day the Earth Stood Still." (Klaatu Barata Nikto -- http://en.wikipedia.org/wiki/Klaatu_barada_nikto)
The one-legged Hopper was ideal for studying dynamic balance because it could not stand still, but had to keep moving to stay upright. The lessons learned with the Hopper proved central for biped, quadruped, and even hexapod running. NavLab 5's crowning achievement was "No Hands Across America," a 1995 cross-country tour on which it did 98 percent of the driving.
CMU plans a formal induction ceremony for the four robots in the fall. http://www.cmu.edu/news/archive/2007/May/may15_rhof.shtml
QSecure, Inc., a SV startup with multiple patents in credit card authentication technology, has announced new technology that significantly reduces fraud resulting from stolen card data. The company's SmartStripe technology protects against counterfeit fraud without requiring changes in retail systems or card holder behavior.
SmartStripe technology incorporates dynamic cryptography on the card's magnetic stripe, augmenting the static data on the magnetic stripe. Each time a consumer uses a SmartStripe card, a proprietary magnetic media chip embedded in the magnetic stripe programs a unique cryptographic number on the stripe that is valid for only one transaction. If the payment card's data is compromised, and criminals attempt to re-use the data from the stripe, card issuers will be able to stop the transaction in real time.
Unlike other solutions which require changes to the existing credit card infrastructure, QSecure's technology works seamlessly within the existing retail system, requiring no modifications to merchants' card readers. Further, its usage is transparent to the card holder, so no changes to buying behavior are necessary. Future versions of QSecure solutions will incorporate a small, flexible display to secure online and other card-not-present transactions. The company is now working on programs with major card issuers.
Talkback: Discuss this article with The Answer Gang
 Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
By Silas Brown
If you want to connect multiple computers to a cable modem then you normally need a router with at least two network ports. One port talks to the cable modem, and the other port(s) talk to the rest of the network. The connections are multiplexed so that the cable modem sees only one machine, and the router can also act as a firewall.
Sometimes it's not feasible to obtain a machine with two Ethernet ports. This might be the case for example if you are working on a temporary and/or test setup and don't have the time or the resources to order extra hardware. My motivation for writing this article was Kapil Hari Paranjape's article "Debian on a Slug" in LG #138, in which he needed to use either two separate networks (Ethernet and wi-fi) or a network with an existing firewall/router in order to set up the NSLU2 (the "slug"), and I wanted to see if it's possible to do without that extra hardware. Especially if the slug is going to be a router/firewall, it seems a little excessive to require another one before you can set it up.
In this article I present some notes on how I constructed a router and firewall using just one Ethernet port on a Linux machine. It wasn't stable enough for long-term use, but it was adequate for temporary situations that call for sharing a cable modem between two or three machines.
A cable modem is basically a network bridge, repeating selected packets from your network to the provider's network and vice versa. It is usually a transparent learning bridge conforming to the IEEE 802.1d standard; it "learns" a number of your Ethernet addresses, and the ISP usually limits this number to one. If it sees additional Ethernet addresses then it will simply ignore them. That is why you usually need to switch the modem off and on again when moving it from one machine to another.
If the modem is going to ignore any machine except the first one it sees, then there is nothing in principle to stop that first machine from acting as a router for other machines even on the same Ethernet segment. For example, consider the following setup:
4-port Unswitched Ethernet Hub
port 1 port 2 port 3 port 4
| | | |
Modem Machine A Machine B Machine C
The hub simply repeats any traffic it receives, because it's unswitched. (In fact it's possible to make do with some simple wire connections; more on this later.) Therefore, the modem sees all traffic from all machines, and conversely all machines see the traffic from the modem. However, the modem will refuse to communicate with anything except the first machine it sees. Suppose that this is Machine A. If Machine B wants to send to the outside world, it first sends to Machine A (and the modem ignores this), then Machine A repeats it (and the modem takes it). Then the reply is addressed by the modem to Machine A (which Machine B will ignore unless its Ethernet interface is set to promiscuous mode) and Machine A can repeat it for Machine B. Note that no machine needs more than one ethernet port.
This approach is inefficient because everything has to be repeated twice on the same wire. Even though Ethernet is generally much faster than broadband, the repetitions can still reduce the speed because they always congest every transmission. In spite of this, the setup can still run at a reasonable speed, especially if your adapters are all 100Mbps or more.
If you have a powered hub or switch then you can skip to the next section.
Some cheap devices called "ethernet splitters" are essentially passive hubs. Care should be taken though because sometimes other things are also sold as "ethernet splitters", such as devices to use the spare wires in an Ethernet cable for another connection, and that's not useful in this setting. If you do find (or even make) a simple unpowered passive hub or "ethernet splitter", you have to think about certain characteristics of Ethernet that can make this more complex than using a powered hub.
10-base-T wiring has different wires for transmit and receive. If several computers are connected using a hub, then what should happen is, if any computer sends data on its "transmit" line, then this data will be placed on the "receive" lines of all the other computers (or perhaps not all of them if it is a switched hub).
Some simple "ethernet splitters" merely connect all the "transmit" lines together and all the "receive" lines together, so none of the machines can actually exchange data unless one of them crosses its connection (receives on the shared "transmit" line and transmits on the shared "receive" line). Cable modems do normally cross their connections, so those "ethernet splitters" are intended to allow all the machines to communicate with the modem although not with each other. This is not very useful in the one-port router setup.
It would be more useful if all machines could communicate with the router rather than with the modem. This can be arranged by connecting the router to the hub with a cross-over cable (or cross-over adaptor), and using normal straight-through cable everywhere else. That way the router's "transmit" is connected to the "receive" of all the other machines and vice versa. It might be necessary to use a second cross-over cable to connect the modem to the hub, in order to cancel out the modem's own crossing-over (or, equivalently, everything except the router and the modem), but most modern cable modems will automatically adapt anyway; just make sure the router is the first machine to boot up.
Further problems can be caused by the polarity auto-detection that's done by Ethernet devices with auto-MDIX ports, and unfortunately there's no way to turn that off other than to use old hardware that doesn't have such auto-detection. (Many Ethernet cards have commands to turn off auto-negotiation of speed and duplex, but not polarity.) There should be no problems when connecting the first two devices to the hub (i.e. the router and the modem), but when the third device is added, if that third device has an auto-MDIX port then it may or may not guess the correct polarity depending on which device it sees first (remember they are opposites). You might have to repeatedly disconnect and reconnect the new device until it sees the router, and if that new device is an NSLU2 which you are trying to connect to a desktop router during the initial setup stage then you'll have to reboot it on every attempt.
To save the hassle of repeated connections (and possibly reboots) of the new device, you could try the following: After connecting only the router and the modem to the hub and verifying that the router can reach the outside world (i.e. the modem has learned its MAC address), disconnect the modem from the hub (but without powering it off) and connect only the new device to the hub. Wait until you can ping the new device, and then reconnect the modem (you may have to reconnect the modem more than once before it will work). This allows the device to negotiate polarity in a less confusing environment, while still allowing the modem to see the router first.
You may have to follow this proceduce if the router itself has an auto-MDIX port and the new device does not, because it's then possible that the router and the modem will have negotiated a polarity that won't work with the new device no matter how many times it's re-connected, so the only option is to disconnect the modem while the router detects the polarity of the new device.
If the new device does have auto-MDIX then in some cases it may help to make sure that the network is as quiet as possible when connecting it. This is because return traffic from the modem is likely to increase the probability of the new device guessing the wrong polarity.
Finally, you may experience problems with the cables themselves. If the hub has no power then it can't amplify the signal, so if the cables are somewhat too long, or if there are cables that are connected at the hub but not connected to anything at the other end (or the device they are connected to is switched off), then this can harm the signal too much and the network will stop working, so try to use shorter cables and don't put any cable on the hub until it's active. Also, beware of fiddly connectors: it took me many hours to track down a fault that was caused by one of the Ethernet plugs working intermittently because I had damaged it while connecting things.
Linux lets you run multiple IP addresses on the same interface, using "aliases". This is useful if you want the router to appear with a private 192.168 address for the local network, but with whatever address it is assigned for the ISP. After the router has DHCP-negotiated with the ISP using dhclient or equivalent, you can do this:
ifconfig eth0:1 192.168.1.1 netmask 255.255.0.0
replacing eth0 with whatever other interface you are using if necessary. The :1 can also be :2, :3 etc to add more IP addresses; you can have up to 256 different IP addresses on the same interface if you want.
Note: This article assumes that your upstream DHCP server does not give you an IP address that is within the 192.168 subnet. If it does (which may be the case if your outgoing connection is shared privately) then you could replace 192.168 with 172.16 throughout this article, because 172.16 is also reserved for private use. You may have difficulty performing initial set-up of an NSLU2 if you cannot control 192.168 however.
Once you have a local-network IP, you can then you can switch on NAT connection forwarding:
modprobe iptable_nat iptables -t nat -A POSTROUTING -j MASQUERADE iptables -P FORWARD ACCEPT echo 1 > /proc/sys/net/ipv4/ip_forward
It may also help to allow the local 192.168 network to access any services running on the router, if its firewall does not already allow this:
iptables -A INPUT -d 192.168.1.1 -j ACCEPT
You may also wish to run a DHCP server for the local network, to save having to manually configure your other machines' IP addresses. This usually means installing a package like dhcp and putting something like the following into /etc/dhcpd.conf:
subnet 192.168.0.0 netmask 255.255.0.0 {
range 192.168.1.100 192.168.1.199;
option routers 192.168.1.1;
option domain-name-servers 192.168.1.1;
}
and then run or restart dhcpd. When putting all this in the system startup scripts, check that the above commands run before dhcpd (in a default Debian installation it suffices to put them at the end of the start) section of /etc/init.d/networking).
It may also help to ensure that dhclient waits to be assigned an address by an outside DHCP server, not by the DHCP server running on the same machine (which may respond first, especially if the outside server goes down for a while). To do this, put
reject 192.168.1.1;
into dhclient.conf (usually in the /etc/dhcp3 directory). This is not necessary if you are setting up a one-off router manually and do not need it to work at system startup, because in that case the DHCP client will likely have obtained an outside address before you can type the commands.
Note that the above option domain-name-servers in dhcpd.conf will work only if the router is running a DNS cache such as pdnsd (available as a Debian package); if you don't want to run that extra server then you'll have to arrange for the upstream DNS server to be copied into dhcpd.conf.
The above commands are reasonably secure by default. While it is relatively easy for someone on the outside Internet to send a packet to your router with a fake 192.168 source IP, they will not normally be able to set the destination to anything other than your router's public IP address, which means they will not be able to access any private servers that are open only on your router's 192.168 address (that's why the above INPUT rule uses -d to specify the destination IP address as being 192.168.1.1, rather than simply constraining the source IP). Also because of the natural constraint on the destination IP, they will not be able to access any of your computers other than the router (even if you have a hub that allows everything to see the modem traffic), nor will they be able to get your router to help forward their packets either to your network or to elsewhere.
However, there are some circumstances in which it is possible for an attacker to deliver packets into your network with a destination IP address other than that of your public IP. This can happen if the attacker takes over your ISP's equipment, or if your ISP's equipment allows source routing, or if the attacker breaks into the connection on your side of the ISP. If you wish, you can take extra steps to protect your private network from this kind of attack.
Such steps involve both protecting the router itself, and ensuring that it is not possible to place packets on the network that bypass the router.
The router itself can be protected by adding MAC-address rules so that it accepts packets only from the known MAC addresses of your network adapters and does not accept inappropriate packets from the modem. See the iptables(8) man page for details. Note that cable modems' MAC addresses have been known to change at power-cycling, so it's better to make a list of all your other MAC addresses. In order to get past this test, an attacker would either have to get packets onto your network by some means other than via the cable modem, or else break into the modem itself or (in some cases) the ISP's head node.
You could get the other machines on your network to also recognise unwanted packets by MAC address, but you may have some machines that cannot run firewalls, and if they can see the traffic from the cable modem before it gets to the router then you could have a problem if an attacker can fake destination IP addresses. The best workaround to this is probably to use a simple "ethernet splitter" hub (see the above section) which physically prevents traffic from bypassing the router even though the router has only one port.
If the private network is such that all the machines can see the router but they cannot see each other, then, if you need them to be able to communicate with each other, you need to arrange for this to go through the router even though they're on the same subnet. This is not too difficult if you can manipulate their route tables by hand, but it's slightly more difficult with DHCP (and note that most DHCP client implementations don't support all the extra options). You could simply set up port-forwarding rules on the router and have the other machines explicitly connect to the router rather than to each other (more on port-forwarding below). A more transparent solution (but more complex to set up) is to arrange for the router to listen on many different IP addresses, each on a very small subnet (with a very narrow network mask) and to allow only one DHCP-allocable address on each of these subnets. At any rate, expect the network speed to be less than what it would be if you had a proper switch, because everything is being repeated.
One final thing you may wish to do is to forward ports, both to make allowances for running public servers such as a Web server, and to facilitate communication between the machines on the private network if they can't see each other (see previous section).
If the server is run on the router itself then this is simply a matter of ensuring the router's firewall allows incoming connections on that port, if it does not already do so. (When specifying that the server is for the private network only, remember that restricting the destination to 192.168.1.1 is more secure than restricting the source for the reasons discussed in the security section above.)
The general way to do port forwarding with iptables (which is more lightweight than setting up some process to listen on the port and forward connections) is this:
iptables -t nat -A PREROUTING -p tcp -d $PUBLIC_ADDRESS --dport $PUBLIC_PORT -j DNAT --to $REAL_ADDRESS:$REAL_PORT iptables -t nat -A POSTROUTING -p tcp -s $REAL_ADDRESS --sport $REAL_PORT -j SNAT --to $PUBLIC_ADDRESS:$PUBLIC_PORT
where PUBLIC_ADDRESS and PUBLIC_PORT are set to the public IP address of the router and the port you want the server to appear on, and REAL_ADDRESS and REAL_PORT are where the server is actually running on the local network. Note that this method can only make the server visible on one interface: either the router's public IP address, or the private 192.168.1.1 address, or localhost if you use OUTPUT instead of PREROUTING, but not more than one of these at the same time. If you require more than one interface to forward to the same server then you'll have to set up a process to listen and forward connections, such as by connecting inetd to nc, or even by using ssh, which is rather overkill for a private network but it's probably the least difficult way to set up forwarding).
If you do use iptables to forward ports for the public interface then you need to set PUBLIC_ADDRESS to the IP that your ISP gives you. You will likely find that your distribution's /etc/dhcp3/ has a dhclient-exit-hooks script or dhclient-exit-hooks.d directory (see man dhclient-script) in which you can place commands such as:
if [ $reason = BOUND -o $reason = RENEW -o $reason = REBIND -o $reason = REBOOT ]; then # new IP will be placed in $new_ip_address # may need to flush the tables (e.g. changed IP) iptables -t nat -F PREROUTING iptables -t nat -F POSTROUTING # ... then add the rules here, using $new_ip_address # and finally re-add the masquerade rule # (because it would have been deleted by the above flush) iptables -t nat -A POSTROUTING -j MASQUERADE fi
You may also need to take some care when setting REAL_ADDRESS to make sure that it is always the same, either by configuring that machine manually (without DHCP) or by noting its MAC address and giving that a fixed-address in dhcpd.conf (see man page for details).
If you use the voice-over-IP application "Skype", it can sound better if you open a port for it in this way and thus avoid the need for your connections to be relayed. For best results open UDP as well as TCP (i.e. repeat the above forwarding setup twice, once as-is and once substituting -p udp for -p tcp in both commands), and tell Skype about the port in Tools/Options/Advanced, but don't tell Skype until after the port is open, because Skype may not save the setting if it does not appear to work at the time. If you use Skype from more than one machine then you can give each one a different public port.
The above discussion of routing commands is probably more in-depth than you need for a temporary setup, but it is included because you might find that your setup is actually stable and you don't need a multi-port router after all. If you do need a multi-port router then you can use your one-port router settings as a reference when configuring the multi-port version.
In my trials with the NSLU2, a desktop, a laptop and a cable modem on a simple "Ethernet splitter" unpowered hub, when the NSLU2 was fully set up as a slug and was itself acting as the one-port router, it often lost connectivity, sometimes to the point of having to be rebooted (not just disconnected and reconnected from the network), if it processed large amounts of traffic for too long ("too long" being anything from seconds to minutes). Extreme throttling of the traffic and packet sizes did help to avoid this, but it made the connection worse than dial-up. However, when the desktop PC was acting as the one-port router on the same network, that problem did not occur. As is so often the case, "Your Mileage May Vary". But it may at least be useful to know that, if you're in a desperate situation, you can rig up a router/firewall on a machine with only one Ethernet port.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/brownss.jpg)
Silas Brown is a legally blind computer scientist based in Cambridge UK. He has been using heavily-customised versions of Debian Linux since 1999.
Working as a Unix Engineer for a large manufacturing corporation puts me in contact with many types of systems and services, and one of the tools for system monitoring I employ is the open source application Hobbit. Monitoring applications make excellent early-warning systems, and can help prevent large-scale network and server problems. In many cases, they can warn you when things are about to go wrong, which is much better than getting panicked phone calls in the middle of the night. Hobbit is a great example of such a watchdog. Hobbit is a compiled binary replacement for Big Brother, and it offers more functionality and improved speed over the original. While Hobbit comes with many of the most common network and system tests right out of the box, it is also easy to extend it to monitor things that are specific to your environment.
I will not describe the Hobbit installation procedure here, as this is well documented at the Hobbit home page, instead I will be describing one of the many custom extensions I am using in production.
Hobbit extensions can range from simple shell scripts to full-blown compiled programs and anything in between. As long as you have access to the Hobbit client you can create any test you need and have the results integrated into the Hobbit web page and alert system. My scripting language of choice for writing Hobbit extensions is Perl. There is a large repository of Hobbit/Big Brother extensions that have already been written and contributed back to the community at http://www.deadcat.net.
Using a simple snmp command and some Perl code we can test many services and processes that are not natively available in Hobbit. The first step is to determine the OID and password for the service you wish to check. In this article I will describe how I used this method to get the cpu utilization from an iSeries server, which is functionality that was not included in Hobbit out of the box. The same principles apply to nearly anything that can be grabbed via SNMP. My Hobbit server runs on Solaris, but the commands are the same for linux. The command to get the cpu utilization from an iseries box from the Solaris command line is "snmpget -v1 -c password servername 1.3.6.1.4.1.2.6.4.5.1.0". With this command in hand, we can wrap it in a script that will report the results to the hobbit server.
#!/usr/bin/perl -w
use strict;
# $test will be the name shown in the Hobbit web gui,
# it should be as short as possible
my $test = '400cpu';
# $bbprog is simply the name of the script
my $bbprog = '400cpu.pl';
my ($color, $line, $machine, $warn, $end, $date, $currently);
my $server='servername';
# Issue the snmp command we discussed earlier and store the
# results in $results
my $results = `/usr/local/bin/snmpget -v1 -c public wc400 1.3.6.1.4.1.2.6.4.5.1.0`;
# Split the results into an array, breaking up by spaces
my @results = split / /, $results;
# Grab just the piece we're looking for from the array, and store in $value
my $value = $results[3];
chomp($value);
# If the value comes in at 3000, that means 30 percent, so do some quick
# math on $value
$value = $value/100;
$value = int($value);
# Initially set the test color to "green", we'll turn red if needed to alert
$color = 'green';
# Set some variables to present to the Hobbit server, the first in colon format
my $percent = "\n\nPercentage : $value\n\n";
$currently = "$percent\n\nCPU ok.\n\n\n\n";
# Determine if cpu utilization is too high, if so, turn red
if ( $value > 80 ) {
$color = 'red';
$currently = "$percent\n\nCPU Utiliaztion is high.\n\n";
}
# Prepare line for Hobbit server in correct format
$machine = "$server,amkor,com";
$date = `date`;
chomp($date);
$line = "status $machine.$test $color $date $currently";
system("/usr/local/hobbit/server/bin/bb hobbit_servername \"$line\"";
Now that we have our script ready, it's time to configure the Hobbit client to run it once every five minutes. Open the file clientlaunch.cfg in the etc directory of your Hobbit home directory and add this entry:
[400cpu.pl]
ENVFILE $HOBBITCLIENTHOME/etc/hobbitclient.cfg
CMD $HOBBITCLIENTHOME/ext/400cpu.pl
LOGFILE $HOBBITCLIENTHOME/logs/400cpu.pl
INTERVAL 5m
Now you can restart your Hobbit client, wait 10 or 15 minutes for data to
be collected, then check your Hobbit gui for output similiar to this:
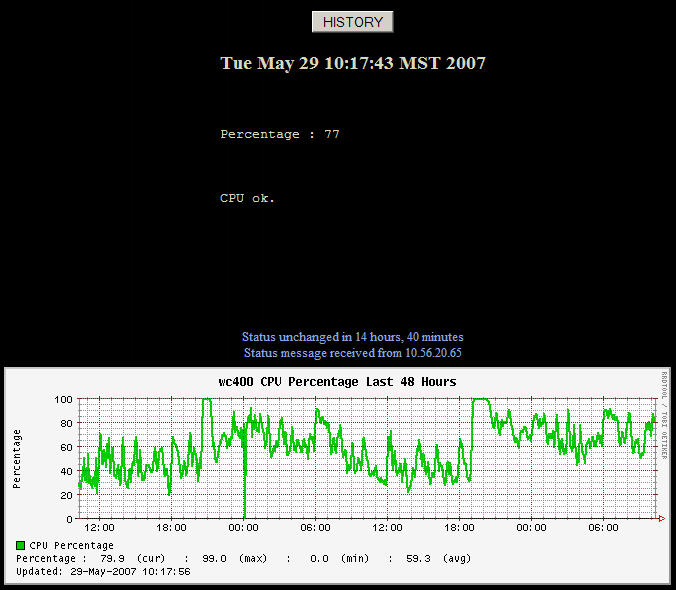
In this brief article, we've managed to create a useful Hobbit test, and have it integrated into the Hobbit gui. Simple variations of this technique can be used to monitor almost any metric that can be gotten to via snmp.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/colello.jpg)
Martin Colello is a unix engineer working for a semiconductor assembly and test company called Amkor Technology. While he is primarily working on Solaris administration, he uses Linux and other OSS software where appropriate to get special projects completed quickly. Most often this is in the area of network, server, and application monitoring using tools such as Hobbit, Cricket, Cacti and Perl scripting.
The outline of next generation web technology is sharper: Web 3.0 is taking shape... today.
This was the third Sem-Tech conference and it was gratifying to see tools and projects emerging and even some early products hitting the new market for Semantic Technologies. The conference focused on both research and the commercialization of ontologies and reasoning tools. It had Tutorials, keynotes, tech sessions and panels. And many developers who had previously discussed novel ideas were now demoing working betas.
This was something of a coming out party for semantic startups and venture capitalists. Besides more business people on panels, poster sessions for academic and open source projects, and informal meetings in the corridors, it was clear that a lot of research was coming out of the lab and becoming productized or open-sourced. Even a giants like Yahoo proudly demoed beta web sites using its Webby version of sematic technology.
(Note: The second Sem-Tech conference was reviewed in LG issue #129, and that article contains definitions and discussions of the underlying technologies. Please refer to it for the terminology of semantic technology [OWL, RDF, etc].)
One example of products slipping into mainstream websites is CongnitionSearch, which is currently used as the advanced search engine at the Lexis-Nexis Concordance service. Dr. Kathleen Dahlberg, a professor at UC Santa Monica and CTO and founder of Cognition, presented a session on the underlying technolgies entitled "Improving Precision and Recall with Lingusitic Semantics".
Cognition Technologies is a search-technology company that has created a meaning-based evolution in text searching. Its patented architecture, known as CognitionSearch, is able to deliver significantly more precise results, with far greater recall, than currently used technologies. In the Medline Demo I saw, a plain text question was parsed by the back end and the user was presented with a small pull down menu to select the correct knowledge domain. The results listed were quite relevant and found word matches not in the original question [!] - e.g., a question on Hogkin's disease found articles on lymphoma ranked near the top. This is due to using taxonomies to process general as well as specific concepts, so a search for "vehicle accident" will find items on cars, buses, boats, etc.
Here is a partial screen snapshot of what the Cognition interface provides:

To view a demonstration of Cognition's technology, please visit www.CognitionSearch.com. Cognition has C++, Java, Perl, Python and Ruby APIs.
Now let's take a look at the semantic tech efforts of the federal government and university research supported by the Disruptive Technology Office (formerly known as ARDA (Advanced Research and Development Activity) - and I am not kidding). Many of these projects still list themselves as ARDA-supported. Although some of the funding comes from those notorious 3 letter agencies, most of this work was never classified and is accessible to the general public.
The revelation here is that ARDA/DTO projects have made significant headway
and have solved, or are solving, many difficult problems in knowledge
representation and machine reasoning. This was the point of a dense
presentation by Dr. Lucian Russell titled "Advanced Intelligence Community
R&D Meets the Semantic Web!"
"Look, the world's greatest minds tried to bring together language and
logic for 50 years and failed. Now it is possible, so as this changes
everything...." Russell went on to describe 4 developments that enables
this paradigm shift, "It starts with English (i.e. WordNet) because that
project (http://wordnet.princeton.edu/)
defines the most common word meanings in the English language. Its database
is the semantics of English." The key here is that, due to WordNet,
machine-mediated semantic analysis is possible.
Besides the availability of a well-defined vocabulary database, ARDA has
produced these technologies:
-- IKRIS, for the representation of
domain-specific knowledge and inter-domain translation
--
AQUAINT, the system used for Advanced Question Answering for
Intelligence
-- TimeML, a markup language for Temporal and
Event expression [http://www.cs.brandeis.edu/~jamesp/arda/time/]
According to Russell, prior to the AQUAINT projects, software systems could not resolve issues involving persistance and temporality, and thus could not read English documents. This lead to the development of TimeML, allowing time stamping, event ordering, and reasoning about processes occurring over time, an essential part of real-world knowledge representation - that is, actions described by verbs.
All of these efforts matured and came to fruition at the end of 2006, and mark a significant advance in semantic interoperability. Together, it is now possible to describe scentific knowledge in language and with logic that is machine readable.
AQUAINT allows a system to answer questions formulated in English based on the content in a repository. For this to occur, the system must parse and understand the question and its relationship to the repository and then find answers in that repository.
Javelin, a multilingual offshoot of AQUAINT being developed at CMU, is currently answering English questions from repositories in Chinese and Japanese. Recently, that research has broadened to questions that involve reasoning about relationships ("How did Egypt acquire SAMs?") and questions that are answered from multilingual sources.
IKRIS has the goal of providing for translation of Knowledge Representations (KRs) from different domains and different contractors. It does this by contextualizing these KRs and and allowing translation of scenarios to support automated reasoning. More specifically, a major goal of IKRIS is to represent knowledge that is relevant to intelligence analysis tasks in a form that enhances automated support for analysts.
"IKRIS is a logic system that encompasses all of the work the W3C did in the OWL language, all of the ISO work on common logic (CL) [http://en.wikipedia.org/wiki/Common_Logic] and extends that to non-monotonic logic, the logic of scientific discovery," Russell said.
A fuller description of AQUAINT and scenario-based analysis is here: [http://languagecomputer.com/hltnaacl04qa/HLT-NAACL-QA-Wkshp-May-04-keynote.pdf]
In 2005 the federal government stated that Semantic Interoperability is a goal. This quote comes from Chapter 3 of the federal Data Reference Model (DRM) documentation: "Implementing information sharing infrastructures between discrete content owners (even with using service-oriented architectures or business process modeling approaches) still has to contend with problems with different contexts and their associated meanings. Semantic interoperability is a capability that enables enhanced automated discovery and usage of data due to the enhanced meaning (semantics) that are provided for data."
"The federal DRM stated that Data Description and Data Context files should be created to enable this sharing but did not say how this would happen," explained Russell. "That was because in 2005 there was no way to specify precisely what "enhanced" meant. As of May 2006, due to the advances by ACQUAINT, there now is. Most important are the results from IKRIS."
One of the benefits resulting from these capabiities is a new relevance for data descriptions and DB documentation - a stepchild in the current IT world and thus a black hole in the IT budget. These are tedious tasks often left undone, or significantly out of date, and hardly anybody would invest time to read these descriptions. But now semantic and linguistic technology can automate the conversion of DB documention into knowledge bases and answer quesitions expressed in natural English - and these can be used to create SOAs and to audit IT policy. A Brave New World is coming...
To achieve this knowledge automation, Russell gave Linux Gazette the following prescription: "The way forward is simple: write precise descriptions of data collections using English. The semantics of each word should be chosen from the meanings of the word in WordNet, augmented as needed. For databases with schemas, the meanings of all data attributes should be described in terms of the processes generating the data values that are stored in the database. Then input the descriptions to a software tool that extracts logical relations from the text." There are several of these arriving on the market and in OSSw projects.
Russell was a co-author of the Data Reference Model, the Federal standard for sharing data. He has been involved with a number of unclassified R&D efforts supporting the Intelligence Community, and helped organize the Semantic Interoperability Community of Practice (SICoP) Special Conferences earlier in 2007.
Here is an earlier version of Russell's presentation as a PPT file from the
April SiCop Conference:
http://colab.cim3.net/file/work/SICoP/2007-04-25/LRussell04252007.ppt
"I will not use the word semantics... if it's done right, no one will know it's there," offered Chuck Rehberg, chief scientist at Semantic Insights. He described their beta product that can read text bases, make inferences and create tailored reports for individuals. He produced reports on all of the presidential candidates based on RSS feeds, showing how semantic matching could generate a selective and relevant report.
Radar Networks, a startup currently in stealth mode, is building a cool next-generation semantic application (the only thing we know with any certainty is that it's not a search engine.) Nova Spivack, its founder, spoke of building end user applications to help groups manage knowledge on the web as a repository. This application is slated to go into an invite-beta status in Fall 2007.
Nova offered this insight: "With group information, the effort increases while the value of the information decreases... it's inversely proprotional to the number of users." The remedy, he suggested, is a layer of semantic tech to help groups manage their knowledge. Said Nova suggestively, "We all have different file systems, email systems, informal knowledge bases... We need to automate that and make sense of all the information."
Another insight: Radar, Vulcan, and some other semantic startups are receiving VC funding from Paul Allen's group. Allen, a co-founder of Microsoft turned technology incubator, is very interested in the potential of semantic tech to intelligently link information on the web.
One notion from a tech session on "Semantic User Experiences" by Ross Centers suggested a way to bridge the developing Web 2.0 universe with semantic technology, often called the future Web 3.0. Drawing a distinction between these approaches, we have a choice of 'tags' vs. formal ontologies (or, as an analogy, something built by web users vs. built by "teams of dwarves locked in mines"). Could the Wiki metaphor bridge the gap? Semantic wikis could act as a way for "crowds" of users to refine a shared ontology, suggested Centers.
Although there were optional tours of Adobe and Oracle to view their semantic products and meet their researchers, most attendees chose a full afternoon product seminar by TopQuadrant to conclude the conference. "Semantic Web Modeling and Application Development using TopBraid" was presented by Dean Allemang and Holger Knublauch of TopQuadrant. This mini-tutorial showed basic modeling in RDF-S and OWL and deployment of a semantic application using TopBraid Live.
Attendees built a simple mashup without having to use the underlying APIs of Google Maps and other sites. Instead, a pre-built ontology was linked to simple data files and back-end processes to graphically build the mashup. In other words, the user drove a knowledge-based tool to create a dynamic, AJAX-based application without programming. This is more than just another level of indirection, and it worked fairly well.
Here's a link to TopQuadrant: http://topquadrant.com/
The Semantic Technology conference scores well in having most presentations on the conference CD (including tutorials), having daily updates of missing presentations and printed tutorial handouts for almost all sessions.
It also scores high on the well-organized meals and snacks, although it could be a little more veggie-friendly. Some rooms for sessions had power cords for attendees, but not the main hall, leading to fierce competition for the few wall outlets.
It looks like the conference proceedings may not be available to the public, since last year's CD is still a commercially-available product. Officially, they will be posting portions of the 2006 and 2007 Semantic Technology Conferences in July. These files will be found on www.aliceinmetaland.com and www.semanticreport.com.
However, at publication time, this link was still open and did not ask for an ID and password: http://www.semantic-conference.com/2007/handouts. Links to the conference tutorials are also available there, and this 188-slide tutorial introducing Sematics and Ontologies with an IT perspective is a good place to start: http://www.semantic-conference.com/2007/handouts/2-UpBW/T1_Uschold_Michael_2UpBW.pdf
Also, here is a link for printable versions of the 2006 presentations:
http://www.semantic-conference.com/Presentations.html
Here are the aggregate ratings [0-10]:
Venue: 6 -- Parking in downtown San Jose is cheaper than SF,
but you have to find it or use Light Rail.
Keynotes: 6 -- One was actually a panel
Session Quality: 7 -- As usual, you
have to search for the gems, but a near complete conference CD helped
Food: 7 -- sit-down meals with dessert
Conference Bag: 8 -- a real, multicompartment shoulder bag
Overall rating: 7
The next Semantic Technology Conference will be held May 18-22, 2008 in San Jose, CA.
Talkback: Discuss this article with The Answer Gang
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Ever since I heard that the new Debian “etch” installer supports encrypted LVM, I wanted to try having an encrypted disk. Given recent news stories about loss of identity information from stolen laptops, it is certainly not paranoid to want to do this — and if you tell me otherwise you are probably one of those guys trying to steal my identity information!
One way would have been to re-install Debian on my laptop from a Debian install CD after saving all my data — but I can already hear sarcastic clucking sounds to the accompaniment of flapping arms folded at the elbows if I even think this way. The whole point of the exercise would be lost if I have to re-configure my laptop all over again. So here goes!
Let me first describe the disk configuration that I like to have as it might be a bit unusual. Ever since I learnt about dmsetup and the Linux Device Mapper stuff, my system has had just two partitions:
This allows me to resize filesystems as and when required. Since
Debian “sarge” I have used the Linux Volume Manager (LVM) rather
than dmsetup to handle this second part. LVM makes it easier to
avoid mistakes while configuring the device mapper.
If your current setup is a more “standard” one that consists of a number of partitions for different purposes, don't worry. As part of the process, your machine too will be configured the same way. “We are the Borg. Your devices will also be mapped out!”
I do need to assume that you have a backup disk that has enough space to hold a copy of your entire system. You don't?! Then let's assume that you have a partition that has enough space to hold a copy of your entire system. What?! You used up all 40GB of diskspace and don't even have a backup!!
In that case, stop reading this article until you have gone and bought yourself that additional disk space. We won't go anywhere. Come right here after you get ready to backup before your system breaks.
So let us assume that /dev/sda contains enough free space to keep a copy of your entire system. This is probably an external USB disk and requires a little more care while booting.
The first step in creating a bootable backup is to install all the tools we will need after we re-boot:
apt-get install cryptsetup lvm2 initramfs-tools grub
apt-get install linux-image-2.6-686
In particular, we will use the stock Debian kernel and the stock Debian boot system (grub+initrd). The order of the install commands is important since we want to make sure that the scripts to handle encrypted and/or LVM disks get installed in the initrd. In case you already have the stock Debian kernel installed you should run
update-initramfs -u
instead of the second step above.
Next, we partition the disk /dev/sda with a scheme like that above:
Next, create a regular ext2 file system on /dev/sda1.
mke2fs -L Boot /dev/sda1
We now setup the other partition as an encrypted LVM partition.
crypsetup luksFormat /dev/sda2
This will ask for a passphrase which will be used to create a Linux Unified Key Setup (LUKS) partition. The partition header of a LUKS parition contains information on how the disk is to be decrypted using a key that is generated using the passphrase.
This passphrase is very important. If you forget it you can forget about all the data in this partition. If you lose it and someone else finds it they can get all the data in this partition.
[ Writing it down on a Post-It note and sticking it to your screen would make a useful reminder... or maybe saving a copy on that newly-encrypted filesystem would be even better. :) If, for some silly reason, you decide that you don't want to follow these time-honored practices, then you might consider saving this password in several places - securely - to prevent loss. -- Ben ]
Next, we get ready to use this partition with the command
cryptsetup luksOpen /dev/sda2 backup
This creates /dev/mapper/backup as a block device containing the unencrypted version of the partition. We will carve this up using LVM2. The commands
pvcreate /dev/mapper/backup
vgcreate vgb /dev/mapper/backup
create an LVM volume group called vgb which will contain the various filesystems. Commands like
lvcreate -n root -L 3G vgb
lvcreate -n swap -L 2G vgb
lvcreate -n home -L 10G vgb
can be used to create the block devices /dev/vgb/root, etc. These can be prepared as usual
mkswap -L Swap /dev/vgb/swap
mke2fs -j -L Root /dev/vgb/root
mke2fs -j -L Home /dev/vgb/home
Well, most of you know the drill, but let me repeat it anyway. First create the empty target tree with commands like
mkdir /tmp/target
mount /dev/vgb/root /tmp/target
mkdir /tmp/target/{boot,home}
mount /dev/vgb/home /tmp/target/home
mount /dev/sda1 /tmp/target/boot
Next, copy the files without looping,
find . -wholename '/tmp/target' -prune -o -print | cpio -pdum /tmp/target
…and go find that cup of coffee with your name written on it. If you are like Chance the gardener in Being There and “like to watch”, then change the -pdum to -pdumv.
Finally, just look through the directory /tmp/target and make sure that you have copied everything properly. This completes the encrypted backup of your system.
The first step is to install grub into the boot record of /dev/sda
grub-install --root-directory /tmp/target /dev/sda
After this you may want to replace the device.map file created
by grub
echo '(hd0) /dev/sda' > /tmp/target/boot/grub/device.map
We also want the /etc/fstab to reflect the new filesystem structure
pushd /tmp/target/etc
mv fstab fstab.orig
cat > fstab <<EOF
LABEL=Root / ext3 defaults,errors=remount-ro 0 1
LABEL=Swap swap swap defaults 0 0
LABEL=Boot /boot ext2 defaults 0 1
LABEL=Home /home ext3 defaults 0 2
EOF
popd
You may want to add the information on how this disk is encrypted
cat >> /tmp/target/etc/crypttab <<EOF
backup /dev/sda2 none luks
EOF
Finally, we need to create the boot instructions for grub. Begin by editing the file /tmp/target/boot/grub/menu.lst at the line that starts with # kopt= and append to it so that the line reads like
# kopt=ro root=/dev/mapper/vgb-root
cryptopts=source=/dev/sda2,target=backup,lvm=vgb-root
rootdelay=10
This is all in one line and has been line wrapped for readability. The rootdelay=10 option gives 10 seconds for the USB disk to be recognised by the Debian boot process; you may need more (or less) time on your system.
You may add options like vga=791 to enable the default VESA framebuffer and so on. Just remember to add these to the same line.
Then incorporate this changed configuration into the boot process
for grub
chroot /tmp/target update-grub
We now unmount the whole mess.
umount /tmp/target/home
umount /tmp/target/boot
umount /tmp/target
Then disable the LVM:
vgchange -an vgb
Remove the decrypted block device:
cryptsetup remove backup
Now, you can safely detach your external USB disk.
And there you have an encrypted bootable backup. It is possible that your laptop does not boot from USB hard disks. In that case you need create a “grub boot floppy” if you want this backup to be bootable!
This is rather easy using rsync.
apt-get install rsync
The command would then be something like
rsync -aW --exclude=/tmp/target \
--exclude=/boot \
--exclude=/etc/fstab \
/. /tmp/target/.
You also need to re-run the grub-install command if you do not
exclude /boot from the backup. Just to avoid blaming your typing
finger you may want to create a script to mount the target, perform
the rsync and unmount the target.
Of course, this still leaves you open to loss of identity information
if your laptop is stolen. So you just boot your newly created
encrypted bootable backup (you need to do that anyway to test it!) and
repeat the above steps with /dev/sda replaced with /dev/hda. You
might also want to replace labels like backup with laptop and
vgb with vg to avoid confusing yourself and your system. You
should probably skip the rootdelay option in this case since you
are booting from the internal disk.
One advantage of converting to LVM is that you can take more “authentic” backups by using “snapshot” images of your system instead of doing a back up while the system is “live”.
Clearly, many thanks go out to the guys who wrote the software that makes all this work. In many cases the source is part of the documentation and so it helps that it is very readable.
Thanks also go to the intrepid reader who actually tries out the above steps. They worked for me, but just in case: “Best of LUKS”.
This document was translated from LATEX by HEVEA.
Talkback: Discuss this article with The Answer Gang
 Kapil Hari Paranjape has been a ``hack''-er since his punch-card days.
Specifically, this means that he has never written a ``real'' program.
He has merely tinkered with programs written by others. After playing
with Minix in 1990-91 he thought of writing his first program---a
``genuine'' *nix kernel for the x86 class of machines. Luckily for him a
certain L. Torvalds got there first---thereby saving him the trouble
(once again) of actually writing code. In eternal gratitude he has spent
a lot of time tinkering with and promoting Linux and GNU since those
days---much to the dismay of many around him who think he should
concentrate on mathematical research---which is his paying job. The
interplay between actual running programs, what can be computed in
principle and what can be shown to exist continues to fascinate him.
Kapil Hari Paranjape has been a ``hack''-er since his punch-card days.
Specifically, this means that he has never written a ``real'' program.
He has merely tinkered with programs written by others. After playing
with Minix in 1990-91 he thought of writing his first program---a
``genuine'' *nix kernel for the x86 class of machines. Luckily for him a
certain L. Torvalds got there first---thereby saving him the trouble
(once again) of actually writing code. In eternal gratitude he has spent
a lot of time tinkering with and promoting Linux and GNU since those
days---much to the dismay of many around him who think he should
concentrate on mathematical research---which is his paying job. The
interplay between actual running programs, what can be computed in
principle and what can be shown to exist continues to fascinate him.
Some people have a need for storing data securely. Sometimes this means not only redundant disks (and a good backup strategy) but also encryption. Fortunately, the Linux kernel has all the features to use multiple RAID devices, pool them to a Logical Volume, and encrypt every block of the filesystem. Just don't forget your passphrase!
The first step involves the creation of a Linux software RAID device. For the sake of simplicity we will stick to RAID level 1, i.e. mirroring two disks or disk partitions. A RAID1 can be done with any two (or more) parts of block devices that have the same size. Usually you mark these partitions when installing the system. The installers of most GNU/Linux distributions have an editor that allows you to do this. We will assume that we already have a system, and prepare four partitions for the use of two RAID1 devices. You simply have to edit the partition table. I like to use the cfdisk tool for that.
osiris:~# cfdisk /dev/sdcPrepare your partitions and mark them with the type code FD. This code marks the partitions as Linux RAID autodetect and allows the system to activate them at boot time. Remember, all the partitions should be of the same size.
osiris:~# cfdisk /dev/sddI chose /dev/sdc1 and /dev/sdd1. Now let's create the RAID. You will need the mdadm tool for this.
osiris:~# mdadm --create /dev/md6 --level=1 --raid-devices=2 /dev/sdc1 /dev/sdd1After pressing enter the kernel creates the device and starts synchronising the blocks. You can check the progress of this operation by looking into /proc/mdstat. This file gives you status of all RAID devices in the system.
osiris:~# cat /proc/mdstat
Personalities : [raid1]
md1 : active raid1 sdb2[1] sda2[0]
3903680 blocks [2/2] [UU]
md5 : active raid1 sdb3[1] sda3[0]
4883648 blocks [2/2] [UU]
md2 : active raid1 sdb5[1] sda5[0]
1951744 blocks [2/2] [UU]
md4 : active raid1 sdb7[1] sda7[0]
297435328 blocks [2/2] [UU]
md6 : active raid1 sdd1[1] sdc1[0]
488383936 blocks [2/2] [UU]
md0 : active raid1 sdb1[1] sda1[0]
489856 blocks [2/2] [UU]
unused devices:
osiris:~#
If you see an output like this, the RAID devices are in a consistent state. The
mdadm packages provides utilities for monitoring the state of RAIDs.
This is very useful otherwise you may not notice when your disks and your RAID
is dying.
Now create a second RAID device. I use /dev/md4 from the output above as the second device to be added to our encrypted logical volume.
Our tool of choice will be cryptsetup for enabling encryption. Before you use block devices as encrypted storage, it is recommended that you overwrite them with random bit patterns. The easiest way to do this is by using dd.
osiris:~# dd if=/dev/urandom of=/dev/md4 osiris:~# dd if=/dev/urandom of=/dev/md6Depending on your hardware this can take several hours. Make sure not to use /dev/random or these commands will take several days or weeks. You don't have to do this. However if you leave any recognisable pattern on the device, it is easier to spot the encrypted blocks, and concentrate code breaking on them.
After your disks have been overwritten with random garbage you can encrypt them.
osiris:~# cryptsetup -c aes-cbc-essiv:sha256 -y -s 256 luksFormat /dev/md4 osiris:~# cryptsetup -c aes-cbc-essiv:sha256 -y -s 256 luksFormat /dev/md6Make sure you don't forget your passphrase! If you forget it, your data is pretty secure and unrecoverable. Bear in mind encrypting data and throwing the keys away is the industrial standard for data destruction (of course assuming that you are using something better than ROT13 or XOR). The block devices are now ready for encryption.
The commands above initialise the devices for use with the AES algorithm. The key length is 256 bit, and we use a method called ESSIV or E(Sector|Salt) in order to avoid weaknesses in the choice of initial values for the encryption algorithm.
Every time you wish to use your encrypted block devices you have to unlock them. That's the idea. Unlocking can also be done with cryptsetup.
osiris:~# cryptsetup luksOpen /dev/md4 crypt1 osiris:~# cryptsetup luksOpen /dev/md6 crypt2You will be prompted for your passphrase. After unlocking, the devices can be accessed by using /dev/mapper/crypt1 and /dev/mapper/crypt2. Note that we won't use the RAID devices directly anymore. We access the storage space through an encryption layer. The data stored in the blocks of our RAID is encrypted.
The Logical Volume Manager (LVM) is a tool for combining multiple physical block devices into volume groups, and for creating logical volumes out of them. The LVM2 has its own HOWTO where everything is explained in great detail. We only need to know how the storage areas are organised. The order is as follows.
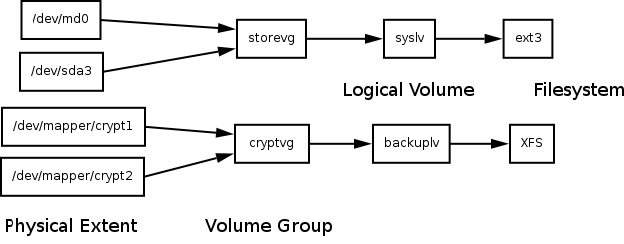
Ok, so let's mark our encrypted RAID1 devices as physical extents and create a volume group.
osiris:~# pvcreate /dev/mapper/crypt1 osiris:~# pvcreate /dev/mapper/crypt2 osiris:~# vgcreate -v cryptvg /dev/mapper/crypt1 /dev/mapper/crypt2The commands pvscan and vgdisplay shows you the result of the commands above. The vgdisplay is especially useful since it shows you the number of physical extents available in a volume group. We now want to use the complete volume group cryptvg for a logical volume. Therefore we tell lvcreate the number of extents to use.
osiris:~# lvcreate -l 191849 -n backuplv cryptvgThat's all we need. Our new logical volume can now be accessed by the device file /dev/backup/backuplv. We format this device with an XFS filesystem (of course you can use whatever filesystem you wish, XFS is just an example).
osiris:~# mkfs.xfs -d agcount=48 -L backup /dev/backup/backuplvThat's it. We can now mount this volume and use it as we like. Don't forget to write an entry for your /etc/fstab in order to have all mount options ready. A possible configuration would be like this one:
/dev/backup/backuplv /backup xfs ikeep,noatime 0 0
You have to do some steps to activate and deactive your new encrypted volume. Most things will be taken care of by the Linux kernel (such as autodetecting the RAID devices and starting them). Some things can't be taken care of automatically. Here is a simple script that does all the necessary steps.
#!/bin/sh echo "Unlocking /dev/md4" cryptsetup luksOpen /dev/md4 crypt1 echo "Unlocking /dev/md6" cryptsetup luksOpen /dev/md6 crypt2 echo "Scanning for volume groups" vgscan --mknodes vgchange -ay echo "Mounting /backup" mount /backupcryptsetup will ask you once per RAID device for your passphrase(s). The shutdown sequence is the reverse order.
#!/bin/sh umount /backup lvremove backuplv vgremove cryptvg cryptsetup remove crypt1 cryptsetup remove crypt2Most GNU/Linux distributions have start/stop scripts that can take care of the activation and deactivation sequences. Nevertheless it's good to know how to do it (maybe for cases when the system isn't available anymore).
Now that your new shiny encrypted logical volume is empty, you have a once in a lifetime chance of testing the storage mechanism. Don't miss to do this! Try simulating a disk failure. Switch off the power and reboot. Do a filesystem check. Create thousands of files and delete them. Copy loads of big ISO images. Do whatever could happen to your storage and see if your data is still there. XFS' mkfs command has the -p switch that allows you to populate a freshly created XFS filesystem with files and directories according to a prewritten description of the filesystem layout. This is a very useful feature for testing. Use it. Simulate everything that can go wrong. When you are satisfied with your testing, put your valuable data on it. And always keep backups.
No blocks or disks were harmed while preparing this article. You might wish to take a look at the following tools and articles suitable to encrypt yourself to death.
Talkback: Discuss this article with The Answer Gang

René was born in the year of Atari's founding and the release of the game Pong. Since his early youth he started taking things apart to see how they work. He couldn't even pass construction sites without looking for electrical wires that might seem interesting. The interest in computing began when his grandfather bought him a 4-bit microcontroller with 256 byte RAM and a 4096 byte operating system, forcing him to learn assembler before any other language.
After finishing school he went to university in order to study physics. He then collected experiences with a C64, a C128, two Amigas, DEC's Ultrix, OpenVMS and finally GNU/Linux on a PC in 1997. He is using Linux since this day and still likes to take things apart und put them together again. Freedom of tinkering brought him close to the Free Software movement, where he puts some effort into the right to understand how things work. He is also involved with civil liberty groups focusing on digital rights.
Since 1999 he is offering his skills as a freelancer. His main activities include system/network administration, scripting and consulting. In 2001 he started to give lectures on computer security at the Technikum Wien. Apart from staring into computer monitors, inspecting hardware and talking to network equipment he is fond of scuba diving, writing, or photographing with his digital camera. He would like to have a go at storytelling and roleplaying again as soon as he finds some more spare time on his backup devices.
[ This is reproduced, with the author's kind permission, from his original post at 'opensource.org'. -- Ben ]
Dana Blankenhorn's story How far can open source CRM get? has finally pushed me to respond to the many people who have asked "When is the OSI going to stand up to companies who are flagrantly abusing the term 'open source'?" The answer is: starting today.
I am not going to start by flaming Dana. As President of the Open Source Initiative, I feel a certain amount of responsibility for stewardship of the open source brand, including both the promotion of the brand as well as the protection of the brand. The topic of "what is really open source and what is not?" has been simmering for quite some time. And until last year the question was trivial to answer, and the answer provided a trivial fix. But things have changed, and its time to regain our turf.
I have been on the board of the OSI for more than 5 years, and until last year it was fairly easy for us to police the term open source: once every 2-3 months we'd receive notice that some company or another was advertising that their software was "open source" when the license was not approved by the OSI board and, upon inspection, was clearly not open source. We (usually Russ Nelson) would send them a notice politely telling them "We are the Open Source Initiative. We wrote a definition of what it means to be open source, we promote that definition, and that's what the world expects when they see the term mentioned. Do you really want to explain to your prospective customers 'um...we don't actually intend to offer you these freedoms and rights you expect?'." And they would promptly respond by saying "Wow! We had no idea!" Maybe once or twice they would say "What a novel idea! We'll change our license to one that's approved by you!". Most of the time they would say "Oops! Thanks for letting us know--we'll promote our software in some other way." And they did, until last year.
Starting around 2006, the term open source came under attack from two new and unanticipated directions: the first was from vendors who claimed that they have every bit as much right to define the term as does the OSI, and the second was from vendors who claimed that their license was actually faithful to the Open Source Definition (OSD), and that the OSI board was merely being obtuse (or worse) in not recognizing that fact. (At least one vendor has pursued both lines of attack.) This was certainly not the first attack we ever had to repel, but it is the first time we have had to confront agents who fly our flag as their actions serve to corrupt our movement. The time has come to bring the matter into the open, and to let the democratic light of the open source community illuminate for all of us the proper answer.
Dana reports correctly when he says:
Then there's open source, the only way in which CRM start-ups can elbow their way into the market today.
And so it is for numerous classes of applications and numerous software markets. But I disagree completely with his next statement, which is logical but also fallacious:
SugarCRM, SplendidCRM and now Centric have proven [sic] there's a place in the market for this (if you read your license carefully).
It is logical precisely because there really is not room in the market for Yet Another Proprietary CRM system. It is fallacious because THESE LICENSES ARE NOT OPEN SOURCE LICENSES. This flagrant abuse of labeling is not unlike sweetening a mild abrasive with ethylene glycol and calling the substance Toothpaste. If the market is clamouring for open source CRM solutions, why are some companies delivering open source in name only and not in substance? I think the answer is simple: they think they can get away with it. As President of the OSI, I've been remiss in thinking that gentle but firm explanations would cause them to change their behavior. I have also not chased down and attempted to correct every reporter who propagates these misstatements (the way that Richard Stallman does when people confuse free software with free beer, or worse--to him--open source). I have now come to realize that if we don't call them out, then they will get away with it (at least until customers realize they've been fooled again, and then they'll blame both proprietary and open source vendors alike; they probably won't be particularly charitable with the press or careless industry analysts, either). If we don't respond to those in the press who fall (or are pushed) into these logical traps, we are betraying the community.
So here's what I propose: let's all agree--vendors, press, analysts, and others who identify themselves as community members--to use the term 'open source' to refer to software licensed under an OSI-approved license. If no company can be successful by selling a CRM solution licensed under an OSI-approved license, then OSI (and the open source movement) should take the heat for promoting a model that is not sustainable in a free market economy. We can treat that case as a bug, and together we can work (with many eyes) to discern what it is about the existing open source definition or open source licenses made CRM a failure when so many other applications are flourishing. But just because a CEO thinks his company will be more successful by promoting proprietary software as open source doesn't teach anything about the true value of open source. Hey--if people want to try something that's not open source, great! But let them call it something else, as Microsoft has done with Shared Source. We should never put the customer in a position where they cannot trust the term open source to mean anything because some company and their investors would rather make a quick buck than an honest one, or because they believe more strongly in their own story than the story we've been creating together for the past twenty years. We are better than that. We have been successful over the past twenty years because we have been better than that. We have built a well-deserved reputation, and we shouldn't allow others to trade the reputation we earned for a few pieces of silver.
Open Source has grown up. Now it is time for us to stand up. I believe that when we do, the vendors who ignore our norms will suddenly recognize that they really do need to make a choice: to label their software correctly and honestly, or to license it with an OSI-approved license that matches their open source label. And when they choose the latter, I'll give them a shout out, as history shows.
Please join me, stand up, and make your voice heard--enough is enough.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/tiemann.jpg)
Michael Tiemann is a true open source software pioneer. The one-time author of the GNU C++ compiler and founder of the world's first open source company (Cygnus Solutions in 1989), Michael is now President of the Open Source Initiative as well as Red Hat's Vice President of Open Source Affairs. In the latter role, Michael integrates and informs technology and open source strategies for Red Hat and its partners and customers in the public and private sectors. Michael provides financial support to the Electronic Frontier Foundation, the GNOME foundation, the Free Software Foundation, and other organizations that further the cause of programming freedom.
These images are scaled down to minimize horizontal scrolling.
All HelpDex cartoons are at Shane's web site, www.shanecollinge.com.
Talkback: Discuss this article with The Answer Gang
 Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
The Ecol comic strip is written for escomposlinux.org (ECOL), the web site that supports es.comp.os.linux, the Spanish USENET newsgroup for Linux. The strips are drawn in Spanish and then translated to English by the author.
These images are scaled down to minimize horizontal scrolling.
All Ecol cartoons are at tira.escomposlinux.org (Spanish), comic.escomposlinux.org (English) and http://tira.puntbarra.com/ (Catalan). The Catalan version is translated by the people who run the site; only a few episodes are currently available.
These cartoons are copyright Javier Malonda. They may be copied, linked or distributed by any means. However, you may not distribute modifications. If you link to a cartoon, please notify Javier, who would appreciate hearing from you.
Talkback: Discuss this article with The Answer Gang
By Samuel Kotel Bisbee-vonKaufmann
Our Geekword Puzzle editor, Sam Bisbee, has now gone off to become the
Wizard-in-Residence to some lucky company - which means that he will no
longer have the time to create the GP. Great for them... less so for us,
although we certainly wish Sam the best of luck. Dear readers, if you know
someone who is a puzzlemaster (is that the right word?), please steer them
in our direction; the Geekword is something we'd hate to lose as a feature.
This is yet another way you can give back to the Linux community - not
something you'd normally expect from that skillset!
-- Ben Okopnik, Editor-in-Chief
|
1
P
|
2
C
|
3
L
|
4
I
|
5
S
|
6
P
|
* |
7
T
|
8
H
|
9
O
|
10
U
|
11
S
|
12
A
|
13
N
|
14
D
|
|
15
S
|
C
|
A
|
M
|
P
|
I
|
* |
16
S
|
A
|
N
|
S
|
E
|
R
|
I
|
F
|
|
17
D
|
A
|
E
|
M
|
O
|
N
|
* |
18
L
|
I
|
C
|
E
|
N
|
C
|
E
|
S
|
| * | * | * |
19
L
|
O
|
G
|
20
A
|
O
|
K
|
H
|
I
|
T
|
* | * | * |
|
21
S
|
22
T
|
23
A
|
R
|
L
|
E
|
A
|
G
|
U
|
E
|
* | * |
24
E
|
25
S
|
26
H
|
|
27
A
|
S
|
H
|
* | * |
28
R
|
H
|
O
|
* |
29
E
|
30
R
|
31
R
|
A
|
T
|
A
|
|
32
S
|
H
|
E
|
33
E
|
34
P
|
* |
35
U
|
N
|
36
E
|
T
|
H
|
I
|
C
|
A
|
L
|
| * | * | * |
37
B
|
A
|
38
S
|
H
|
* |
39
S
|
A
|
S
|
H
|
* | * | * |
|
40
T
|
41
A
|
42
B
|
A
|
R
|
O
|
U
|
43
N
|
D
|
* |
44
E
|
L
|
45
V
|
46
E
|
47
S
|
|
48
A
|
D
|
A
|
Y
|
T
|
O
|
* |
49
E
|
E
|
50
F
|
* | * |
51
K
|
S
|
H
|
|
52
Z
|
S
|
H
|
* | * |
53
T
|
54
E
|
S
|
T
|
I
|
55
F
|
56
I
|
E
|
R
|
S
|
| * | * | * |
57
C
|
58
U
|
H
|
R
|
T
|
L
|
O
|
N
|
F
|
* | * | * |
|
59
B
|
60
I
|
61
N
|
O
|
M
|
I
|
A
|
L
|
* |
62
L
|
A
|
D
|
63
D
|
64
E
|
65
R
|
|
66
R
|
E
|
S
|
P
|
O
|
N
|
S
|
E
|
* |
67
I
|
M
|
O
|
V
|
E
|
A
|
|
68
I
|
V
|
O
|
Y
|
A
|
G
|
E
|
D
|
* |
69
L
|
E
|
W
|
D
|
L
|
Y
|
|
Across 1: Franz Lisp for MS-DOS 7: First column of four digit number 15: Scali's Message Passing Interface 16: Arial and Impact, for example 17: Parent's process is usually init 18: MIT, BSD, Apache 19: 200 in access.log 21: Sun product, s/office/league/ 22: Easy version of this puzzle's theme answers 24: Easy version of this puzzle's theme answers 27: Smaller, faster version of 37A 29: Greek letter, often for density 30: Red Hat security _ (bugs) 33: Used as iterators when sleeping 36: Closed source, to some 38: Version of sh, is a bad pun 40: Shell with static library links 41: Ctrl+Tab repeatedly 42: Germanic creature made popular by Tolkien 45: Germanic creature made popular by Tolkien 49: Epoch, _ remember for programmers 50: 1980s AT&T Bell Labs shell 51: Digital advocacy group 53: 1980s AT&T Bell Labs shell 54: Extends 15A, 21A, and tcsh 56: Supporters 60: 43 55 48 52 54 4C 4F 4E 46 62: Polynomial with two terms 65: Parallel circuit look alike 69: SYN-ACK 70: "Why did _ symlink?" 71: `/(I traveled)/` with synonym 72: Sexy programmers, loudly typing _ |
Down 1: Uses MIME type image/photoshop 2: NFS, AFS, SMB, for example 3: Was Janus (Solaris 10) 4: `perl -e '$_ = "IMMLER";' -e 'print "$1R\n" if /(IMML)?E/'` 5: Mailbox file 6: A box sending ICMP Echo Requests 7: Xvnc or SSH, for ex. 8: DeCSS poem type 9: "The HTML is served _h" (2 wds) 10: "Most coders _ to iterate" (2 wds) 11: _-mail, default Pine folder 12: .zip predecessor by SEA 13: 01101110 01101001 01100101 14: NFS, AFS, SMB, for example 20: `echo A G H I J N O T U V W X | awk '{print $1$1$3$9$3$9}'` 21: Common suite of statistical software 22: _ 9000, or CARL in French 23: read_ad, reads data into the page cache 24: Popular postcardware CD ripper that requires Wine 25: _lin, "an extremely aggressive Scheme compiler" 26: _ 9000, or CARL in French 28: RIHL 31: Red Hat += Security-Enhanced Linux (abbr) 32: RIHL 34: Popular "going once, going twice" website 35: "You don't leave an IRC channel, you _ it" 37: Spanish, German, and Tagalog 39: Open source, _ coders one at a time 41: Crazed Looney Toons character 42: Specifies SHA-1, SHA-256, SHA-512, for example 43: "_, humbug!" 44: XML, tags _ among other tags 46: _ybd, virtual on-screen midi keyboard 47: Controversial open software advocate 48: Specifies SHA-1, SHA-256, SHA-512, for example 52: `perl -e 'print "Use ". reverse $answer ." GRUB is not available.\n"'` 55: _n, deconfigure 57: `rm` synonym 58: i_s, extracts CPP conditionals 59: _n, deconfigure 60: `cp` 61: VU1PQQ== 62: Network _dge, links network segments at the data link layer 63: Sun _, a stateless thin-client 64: "War Games" gov't agency, s/A/O/ 66: 8D decrypts this 67: GNOME widgets by Nautilus hackers 68: Sun _, a stateless thin-client |
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/bisbee.jpg)
Samuel Kotel Bisbee-vonKaufmann was born ('87) and raised in the Boston, MA area. His interest in all things electronics was established early as his father was an electrician. Teaching himself HTML and web design at the age of 10, Sam has spiraled deeper into the confusion that is computer science and the FOSS community, running his first distro, Red Hat, when he was approximately 13 years old. Entering boarding high school in 2002, Northfield Mount Hermon, he found his way into the school's computer club, GEECS for Electronics, Engineering, Computers, and Science (a recursive acronym), which would allow him to share in and teach the Linux experience to future generations. Also during high school Sam was abducted into the Open and Free Technology Community (http://www.oftc.org), had his first article published, and became more involved in various communities and projects.
Sam is currently pursuing a degree in Computer Science at Boston University and continues to be involved in the FOSS community. Other hobbies include martial arts, writing, buildering, working, chess, and crossword puzzles. Then there is something about Linux, algorithms, programing, etc., but who makes money doing that?
Sam prefers programming in C++ and Bash, is fluent in Java and PHP, and while he can work in Perl, he hates it. If you would like to know more then feel free to ask.
Benjamin A. Okopnik [ben at linuxgazette.net]
Sun, 03 Sep 2006 09:37:22 -0400
On Sun, Sep 03, 2006 at 09:11:55AM -0400, Benjamin Okopnik wrote:
> Speaking of separate partitions...
Whoops. Actually, that was Mark Baldridge, not me. I forwarded to TAG, but clipped the 'forward' lines; silly me.
* Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (7 messages/5.94kB) ]
Rick Moen [rick at linuxmafia.com]
Tue, 18 Jul 2006 13:51:03 -0700
-- forwarded message --
Path: be01!atl-c01.usenetserver.com!news.usenetserver.com!pc02.usenetserver.com!TSOFT.COM-a2kHrUvQQWlmc!not-for-mail
From: Rick Moen <rick@linuxmafia.com>
Subject: Re: root kits on linux
Newsgroups: alt.os.linux.suse
References: <44b9af59$0$22362$afc38c87@news.optusnet.com.au>
Organization: If you lived here, you'd be $HOME already.
User-Agent: tin/1.8.1-20060215 ("Mealasta") (UNIX) (Linux/2.4.27-2-686 (i686))
Message-ID: <99869$44bd47ee$c690c3ba$15047@TSOFT.COM>
X-Complaints-To: abuse@usenetserver.com
Date: Tue, 18 Jul 2006 16:43:26 -0400
Lines: 29
X-Trace: 9986944bd47ee6335661f15047
Xref: usenetserver.com alt.os.linux.suse:401414
X-Received-Date: Tue, 18 Jul 2006 16:43:26 EDT (be01)
Spoken4 <random_net_reg@optusnet.com.au> wrote:
> Is linux susceptible to root kits?
Rootkits (i.e., kits of software designed to hide an intruder's presence) are a minor after-effect of system security compromise that has already occurred through other means entirely. Your question is similar to asking: "Are houses susceptible to being burned down?", because you heard of a case where a house was left derelict for years, the front door rotted, vagrants moved in and trashed the place for a couple of more years, and finally one of them dropped a match.
> The recent talk of these as ways of attacking pc's and the Sony > debacle has left me wondering. Apart from regularly updating my > system, is there a way I can check that I haven't been compromised (if > 10.1 is at risk)?
You actually ask a profound question: How do you ever know for certain that a system hasn't been compromised by unauthorised parties? The literal answer is: You can't. A slightly more useful answer from Marcus J. Ranum is that you minimise the likelihood of compromise this way: 1. Don't use software that sucks. 2. Absolutely minimise Internet-facing network services your system offers.
These may also help:
http://linuxgazette.net/issue98/moen.html
http://linuxmafia.com/~rick/lexicon.html#moenslaw-security3
http://linuxmafia.com/~rick/faq/index.php?page=virus#virus5
http://security.itworld.com/4352/LWD000829hacking/pfindex.html
-- end of forwarded message --
Rick Moen [rick at linuxmafia.com]
Wed, 06 Sep 2006 11:20:17 -0700
boggle
[ ... ]
[ Thread continues here (1 message/4.12kB) ]
Benjamin A. Okopnik [ben at linuxgazette.net]
Mon, 28 Aug 2006 12:33:26 -0400
Hi, folks -
Just FYI, I have the minor inconvenience of a hurricane heading for me, and (theoretically) approaching my neighborhood just about the time that I'm supposed to be publishing LG this month. I'm hoping to not have to either a) publish LG from 30,000 feet without a plane or b) miss pubbing on the 1st, but it's looking iffy at the moment.
>From the National Weather Service: FORECAST VALID 30/1200Z 26.6N 80.4W...INLAND MAX WIND 70 KT...GUSTS 85 KT. 50 KT... 50NE 50SE 25SW 25NW. 34 KT...120NE 120SE 50SW 50NW. FORECAST VALID 31/1200Z 31.0N 80.0W MAX WIND 75 KT...GUSTS 90 KT. 50 KT... 50NE 50SE 30SW 50NW. 34 KT...120NE 120SE 75SW 90NW.
So, the current prediction is that around 1000 Zulu on the 31st (i.e., ~3a.m. EST on the 1st), the center of the hurricane - which will be blowing about 75 knots steady and gusting 90 knots - is going to visit my neighborhood (29.9N 81.3W).
On the plus side, I recently bought a large anchor and some chain for it. On the minus side, my engine is down for service at the moment, and getting the boat to a hurricane hole without an engine is problematic, to say the least. I'll be beavering away on that latter problem, and keeping track of Ernesto as it spins its way toward me...
* Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (15 messages/22.37kB) ]
Rick Moen [rick at linuxmafia.com]
Tue, 26 Jun 2007 00:02:09 -0700
----- Forwarded message from rick ----- Date: Fri, 22 Jun 2007 13:51:14 -0700 To: conspire@linuxmafia.com Cc: Karsten Self <karsten> Subject: Seen on Groklaw
Patents In Linux
Authored by: DannyB on Tuesday, June 19 2007 @ 01:21 PM EDT
Microsoft: So, it is down to you, and it is down to me...if you wish Linux dead, by all means keep moving forward.
IBM: Let me explain...
Microsoft: There's nothing to explain. You're trying to free what I have rightfully stolen.
[ ... ][ Thread continues here (1 message/5.48kB) ]
Talkback: Discuss this article with The Answer Gang
Jimmy has been using computers from the tender age of seven, when his father
inherited an Amstrad PCW8256. After a few brief flirtations with an Atari ST
and numerous versions of DOS and Windows, Jimmy was introduced to Linux in 1998
and hasn't looked back.
In his spare time, Jimmy likes to play guitar and read: not at the same time,
but the picks make handy bookmarks.
 Jimmy is a single father of one, who enjoys long walks... Oh, right.
Jimmy is a single father of one, who enjoys long walks... Oh, right.

![[cartoon]](misc/ecol/tiraecol_en-260.png)
{kind=link}