
...making Linux just a little more fun!
Amit Kumar Saha [amitsaha.in at gmail.com]
Hello,
Any of you know how I can extract my 'vmlinuz' to get the 'vmlinux' ?
Thanks, Amit
-- Amit Kumar Saha http://amitsaha.in.googlepages.com http://amitksaha.blogspot.com
[ Thread continues here (3 messages/1.88kB) ]
mahesh war [b.maheshwer at gmail.com]
Hello sir,
This is B.Maheshwar from ASDLAB Bangalore,currently we are working on parallel port driver,i need your help .can please send if you are having article related to the parallel port driver for linux .
Thanking you.
Regards B.Maheshwar
[ Thread continues here (2 messages/1.37kB) ]
Thomas Bonham [thomasbonham at bonhamlinux.org]
Anyone know of a way to have multiple ssh authorized_keys files for host key authentication for different users. I am familiar with the usual practice of echoing all of the users keys into authorized_keys file but I am thinking in terms of if I have to revoke keys and disable user access. What I would like to do is have a setup similar to apache in that it can have files included in the conf directory. So this way I have a user name or identifying indicator of whose key is whose so I can revoke access as the necessity arises.
Thank you for all of your help.
Thomas
[ Thread continues here (6 messages/6.15kB) ]
Ben Okopnik [ben at linuxgazette.net]
Oh, this is rather special - in the highly dubious sense of the word. Spammers are now recognizing the value of Linux... for spamming campaigns. Wow.
Comments, anyone?
----- Forwarded message from Patrick Wang <pjwang@fastscale.com> -----
From: Spammer Spammer <spammer@spam.com> To: "editor@linuxgazette.net" <editor@linuxgazette.net> Date: Mon, 10 Mar 2008 18:35:59 -0700 Subject: Need to get a quote on a linux email list ASAP -- can you recommendan email vendor?
Greetings,
We're conducting a time sensitive email marketing campaign and are looking to buy a high quality list and wanted to see if you could provide an email list for this campaign.
-Linux platform and more than 200 servers.
Anywhere in the US and level: IT directors or higher (including CIO, CTO)
If it can be even more granular to include RedHat Enterprise 4 or 5 as well as CentOS 4 or 5, we definitely can use that bit of information. Please call me with any introductions. will your list be opted-in and will we be provided proof for this? We're using Salesforce and VerticalResponse, and need to be able to use VerticalResponse.
Thanks in advance for any help or guidance you can provide.
-- Regards,
Spammer Spammer Senior Sales Manager
Spammer Technology 10101 Spammer Ave
Santa Clara, CA 95051
----- End forwarded message -----
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
Amit Kumar Saha [amitsaha.in at gmail.com]
Hello,
I am currently trying to get some experience using 'Iozone' to obtain some I/O test results on my Linux 2.6 disk partitions. Subsequently, I would like to use my knowledge to do some analysis in a RAID project I am working on.
Do we have anyone here experienced with using the 'Iozone' tool (http://www.iozone.org/) ? It would be nice to know of your experiences.
Thanks, Amit
-- Amit Kumar Saha *NetBeans Community Docs Coordinator* Writer, Programmer, Researcher http://amitsaha.in.googlepages.com http://amitksaha.blogspot.com
[ Thread continues here (5 messages/5.92kB) ]
Rick Moen [rick at linuxmafia.com]
Now, there is a BOfH!
----- Forwarded message from Rory Browne <rbmlist@gmail.com> -----
Date: Wed, 12 Mar 2008 17:24:44 +0000 From: Rory Browne <rbmlist@gmail.com> To: Irish Linux Users Group <ilug@linux.ie> Subject: Re: [ILUG] shell users/scripters, how do you script yours?On Wed, Mar 12, 2008 at 2:39 PM, Gavin McCullagh <gmccullagh@gmail.com> wrote:
> Hi, > > On Wed, 12 Mar 2008, Rory Browne wrote: > > > Returning to the topic, I wouldn't worry too much about executing ls > > once. I think it only becomes a problem when you run an executable > > inside a loop that repeats a lot. > > Fair point, though the fact that a file called "some file" will be treated > as two files called "some" and "file" would be my concern. >
I have a procedure for dealing with when my users put spaces in their filenames.
find / -name '* *' -exec ls -l {} \;
Taking the third column in the output, you get the username, which you can then pipe to ps -u -o pid | xargs -i kill -9 {}
This gives you the list of users with spaces. Some manipulation with Awk, or Perl, can turn this into a list of usernames prefixed with userdel -r, which can then be piped to /bin/sh.
After you've finished deleting your accounts, you can then hire a hitman to ensure that they never receive accounts on any of your systems again.
-- Irish Linux Users' Group mailing list About this list : http://mail.linux.ie/mailman/listinfo/ilug Who we are : http://www.linux.ie/ Where we are : http://www.linux.ie/map/
[ Thread continues here (2 messages/4.90kB) ]
Amit Kumar Saha [amitsaha.in at gmail.com]
Hello,
I started playing with Software RAID sometime back and have posted my notes here at http://amitksaha.blogspot.com/2008/03/software-raid-on-linux-part-1.html
Would be nice to have some feedback/comments.
Ben: Can i contribute to LG as an article?
Thanks, Amit
-- Amit Kumar Saha *NetBeans Community Docs Coordinator* Writer, Programmer, Researcher http://amitsaha.in.googlepages.com http://amitksaha.blogspot.com
[ Thread continues here (16 messages/22.92kB) ]
brad [netcom61 at yahoo.ca]
Hello - A real general question for you linux pros.
What is the serious linux geek's choice of distro? And Why?
[ Thread continues here (12 messages/9.84kB) ]
[ In reference to "Tips on Using Unicode with C/C++" in LG#147 ]
Jimmy O'Regan [joregan at gmail.com]
I was reminded of Ren?'s article while trying to get Apertium to compile with Cygwin, because Cygwin lacks wide string support in g++. I tried to find a canned piece of m4, to give a warning about this at configure time instead of compile time, but, alas, I couldn't find anything and had to write something myself.
Does anyone know enough about configure etc. to find any obvious problems with this?
# Check for wide strings
AC_DEFUN([AC_CXX_WSTRING],[
AC_CACHE_CHECK(whether the compiler supports wide strings,
ac_cv_cxx_wstring,
[AC_LANG_SAVE
AC_LANG_CPLUSPLUS
AC_COMPILE_IFELSE([AC_LANG_PROGRAM([[#include <string>]],[[
std::wstring test = L"test";
int main () {}
]])],
[ac_cv_cxx_wstring=yes], [ac_cv_cxx_wstring=no])
AC_LANG_RESTORE
])
])
AC_CXX_WSTRING
if test "$ac_cv_cxx_wstring" = no
then
AC_MSG_ERROR([Missing wide string support])
fi
[ Thread continues here (3 messages/4.63kB) ]
[ In reference to "A dummies introduction to GNU Screen" in LG#147 ]
Cesar Rodriguez [cesarrd at gmail.com]
Thanks i was using screen but just with rtorrent after your article i don't know how i can live before without screen.
Thanks.
-- Cesar Rodriguez
[ In reference to "Installing Linux on a Dead Badger (Book Review)" in LG#148 ]
Ben Okopnik [ben at linuxgazette.net]
----- Forwarded message from "\"Steve Lawson\"" <steve.lawson@steve.lawson.bbmax.co.uk> -----
To: editor@linuxgazette.net From: "\"Steve Lawson\"" <steve.lawson@steve.lawson.bbmax.co.uk> Reply-To: "\"Steve Lawson\"" <steve.lawson@steve.lawson.bbmax.co.uk> Subject: tkb: Talkback:148/okopnik.html Date: Sun, 02 Mar 2008 18:50:41 +0000Could you ask the author of the review of the book, 'Installing Linux on a Dead Badger', which features in the latest edition of Linux Gazette, what the book is actually about? Having read his admittedly witty and erudite review, I'm still no clearer. Thank you, Steve Lawson Glasgow Scotland
----- End forwarded message -----
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (3 messages/4.54kB) ]
Mulyadi Santosa [mulyadi.santosa at gmail.com]
First, why? Easy, because mp3 is patended format and ogg is open
source format. So, to guarantee your peace of mind (like what Cattano
said to Frank Lucas in "American Gangster"  ), use ogg.
), use ogg.
To do it, first I assume you have mpg123 (http://www.mpg123.de/) installed and the binary is located in searchable path (check your $PATH).
Your mp3 files probably contain spaces, so use this script:
#!/bin/bash for b in *; do ( cd $b; for a in *; do mv -v "$a" $(echo $a | sed s/\ /\_/g); done ) ; done
The script assumes your working directory has subdirectories that holds the mp3 files (think of it as albums). Outer loop lists the directories and inner loop "cd" into them and rename the files inside so they don't contain spaces anymore.
Finally, the real piece of work:
#!/bin/bash
for b in *;
do ( cd $b;
for a in *;
do test=$(echo $a | cut -f1 -d\.).wav ;
mpg123 -v -w $test "$a";
oggenc $test ;
rm -fv $test ; rm -fv "$a" ;
done );
done
In short, the script loops over your collections. It uses mpg123 to convert your mp3s into wavs. Then, oggenc converts it as ogg. The wav is then deleted since we don't need it anymore. Why create wav 1st, you might ask? Well, i tried to pipe mpg123 directly to oggenc but somehow it didn't work (at least in my case), so that's my workaround.
regards,
Mulyadi.
[ Thread continues here (5 messages/8.94kB) ]
By Howard Dyckoff and Kat Tanaka Okopnik

|
|
Please submit your News Bytes items in plain text; other formats may be rejected without reading. A one- or two-paragraph summary plus a URL has a much higher chance of being published than an entire press release. Submit items to bytes@linuxgazette.net.
 Open Source Persistence Framework to provide JPA 2.0
Open Source Persistence Framework to provide JPA 2.0The Eclipse Foundation and Sun Microsystems have selected the EclipseLink project as the reference implementation for Java's JPA 2.0. Sun is the project lead for the Java Persistence API (JPA) and the JSR 317 standard. This is another example of how the Eclipse community has been leading the implementation of JSRs under the Java Community Process (JCP). The Eclipse Persistence Services Project (EclipseLink), led by Oracle, delivers an open source runtime framework supporting major persistence standards.
The EclipseLink project provides a rich set of services addressing complex mapping, performance, and scalability issues required for enterprise Java applications. JSR 317, the Java Persistence API, is the Java API for the management of persistence and object/relational mapping for the Java Platform. As the reference implementation, EclipseLink will provide a commercial quality persistence solution that can be used in both Java SE and Java EE applications.
The EclipseLink project was initiated with Oracle's contribution of the full source code and test suite for Oracle TopLink. The project builds on the success of TopLink Essentials which is featured in Sun's GlassFish Open Source Application Server, the JPA 1.0 reference implementation, which was also based on Oracle TopLink.
More details about the EclipseLink project and JSR 317 can be found at
http://www.eclipse.org/eclipselink/
http://jcp.org/en/jsr/detail?id=317
Other News from EclipseCon 2008At EclipseCon 2008 in March, the Eclipse Foundation announced a new initiative to develop and promote open source runtime technology based on Equinox, a lightweight and OSGi-compliant runtime for applications. While Eclipse is well known for its widely used development tools, this initiative establishes a community of Eclipse open source projects focused on runtime technology that provides a more flexible approach to building and deploying software on mobile, desktop, and server environments.
The move to create a community around Equinox is a logical progression for Eclipse. Equinox, the core runtime platform for Eclipse, has been deployed on millions of software developers' desktops, has enabled an ecosystem of thousands of Eclipse plug-ins, and is the base of hundreds of Eclipse Rich Client Platform (RCP)-based applications. Recently, the community has also used Equinox as the server platform for Ajax applications, SOA, enterprise client/server applications and others. So, this new initiative promotes Equinox as a platform for building and deploying general purpose software products and applications.
More details about the Equinox community can be found at http://eclipse.org/equinox-portal .
Eclipse Higgins 1.0 ReleasedEclipse Foundation announced the availability of Eclipse Higgins 1.0, a freely downloadable identity framework designed to integrate identity, profile, and social relationship information across multiple sites, applications, and devices.
Web 2.0, mashups, social networking, and the general rise of networked applications have made Web-based identity management complex for both end-users and developers. The Eclipse Higgins project has been working to address these issues. Multiple identity protocols have been developed to address different needs, including WS-Trust, OpenID, SAML, XDI, and LDAP.
Eclipse Higgins 1.0 is now available at http://www.eclipse.org/higgins/downloads.php. More information about the project is available at http://www.eclipse.org/higgins .
NSA, Sun to enhance OpenSolaris SecuritySun and the United States' National Security Agency (NSA) announced an agreement to jointly work within the OpenSolaris Community to research and to develop security enhancements to complement existing OpenSolaris security mechanisms. Both Sun and the NSA will work with the OpenSolaris community to integrate an additional form of mandatory access control (MAC), based on the Flux Advanced Security Kernel (Flask) architecture.
The joint research project is intended to complement the security benefits of the mandatory access controls provided by the Solaris(TM) Trusted Extensions feature and will be evaluated by the OpenSolaris community. The Flask architecture supports a wide range of security policies, enabling integration of different policy engines and configuration of the security policy to meet the specific security goals for a wide range of computing environments.
Intel describes Future Multicore ArchitectureIn March, Intel Corporation raised the curtain on upcoming microprocessors and technologies. Intel discussed future products with 45nm high-k metal gate manufacturing technology that will be used in 4-, 6-, 8-, and multi-cores coming to the market.
Pat Gelsinger, Intel Senior Vice-President and General Manager, disclosed details about Intel's 6-core processor codenamed "Dunnington" and Intel's new Itanium processor codenamed "Tukwila." Gelsinger discussed virtualization issues and the new SPEC power benchmark for measuring server energy efficiency, in which Intel-based systems hold the top 20 spots.
Technical features were described for Nehalem, Intel's next-generation processor family, and Larrabee, a future Intel product with many cores. Tukwila is Intel's next-generation Itanium processor with four cores, 30MB total cache, QuickPath Interconnect, and Integrated Memory Controller. Nehalem chips will have from 2 to 8 cores, with 4- to 16-thread capability. Nehalem will deliver four times the memory bandwidth, compared to today's Intel Xeon processor-based systems.
Google I/OGoogle I/O, a two-day, in-depth developer gathering to share knowledge about Google's own developer products and Web application development in general, will be held at the Moscone Center in San Francisco, on May 28th and 29th, 2008.
Google I/O will include practical, hands-on advice for building Web apps as well as opportunities to learn about emerging trends. Sessions with top Google engineers will cover tools developed both inside and outside Google, including yet-to-be-announced initiatives for the World Wide Web.
Five simultaneous topic areas will cover:
The sessions will allow attendees to learn first-hand from Google engineers including Mark Lucovsky, Guido van Rossum, David Glazer, Alex Martelli, Steve Souders, Dion Almaer, Jeff Dean, Chris DiBona, and Josh Bloch. Tickets are $400 for developers, with discounts for students.
More information about Google I/O is available at http://code.google.com/events/io/ .
Google Developer Days Going GlobalBuilding on the success of last year's global Developer Day, Google is taking the event on the road again to multiple cities around the world. Like Google I/O, Developer Day will bring Googlers and developers together to talk about the future of the Web as a platform, but in smaller venues with content tailored to the local market. Dates and locations will be announced in the coming months.
MDM Summit 2008
March 30 - April 1, San Francisco, CA
http://www.sourcemediaconferences.com/MDM/register.html
MuleCon 2008
April 1 - 2, San Francisco, CA
http://www.mulesource.com/mulecon2008/
Sun Tech Days
April 4 - 6, St. Petersburg, Russia
http://developers.sun.com/events/techdays
Gartner Emerging Trends Symposium/ITxpo 2008
April 6-10, Las Vegas, NV
RSA Conference 2008
April 7 - 11, San Francisco, CA
http://www.RSAConference.com
(save up to $700 before January 11, 2008)
2008 Scrum Gathering
April 14 - 16, Chicago, IL
http://www.scrumalliance.org/events/5--scrum-gathering
MySQL Conference and Expo
April 14 - 17, Santa Clara, CA
http://www.mysqlconf.com
Web 2.0 Expo
April 22 - 25, San Francisco, CA
http://sf.web2expo.com
Interop Moscow
Apr 23 - 24, Moscow, Russia
http://www.interop.ru
CSI SX: Security Exchange
Apr 27 - 29, Las Vegas, NV
http://www.CSISX.com
Interop Las Vegas - 2008
April 27 - May 2, Mandalay Bay, Las Vegas, NV
http://www.interop.com/
JavaOne 2008
May 6 - 9, San Francisco, CA
http://java.sun.com/javaone
ISPCON 2008
May 13 - 15, Chicago, IL
http://www.ispcon.com/
Free Expo Pass Code: EM1
Forrester's IT Forum 2008
May 20 - 23, The Venetian, Las Vegas, NV
http://www.forrester.com/events/eventdetail?eventID=2067
DC PHP Conference & Expo 2008
June 2 - 4, George Washington University, Washington, DC
http://www.dcphpconference.com/
Gartner IT Security Summit
June 2 - 4, 2008, Washington DC
http://www.gartner.com/us/itsecurity
Symantec Vision 2008
June 9 - 12, The Venetian, Las Vegas, NV
http://vision.symantec.com/VisionUS/
Red Hat Summit 2008
June 18 - 20, Hynes Convention Center, Boston, MA
http://www.redhat.com/promo/summit/
The 2008 USENIX Annual Technical Conference (USENIX
'08)
June 22 - 27, Boston, MA
Join leading researchers and practitioners in Boston, MA, for 6 full
days on the latest technologies and cutting-edge practices, including
training by industry experts such as Peter Baer Galvin, Bruce Potter,
and Alan Robertson; starting June 25, technical sessions included a
keynote address by David Patterson, U.C. Berkeley Parallel Computing
Laboratory; Plenary Closing by Matthew Melis, NASA Glenn Research
Center; other Invited Talks by speakers including Drew Endy,
co-founder of the BioBricks Foundation (BBF); and the Refereed Papers
track. Learn the latest ground-breaking practices from researchers
from around the globe. Topics include virtualization, storage, open
source, security, networking, and more.
Register by June 6 and save up to $300!
 http://www.usenix.org/usenix08/lg
http://www.usenix.org/usenix08/lg
Dr. Dobb's Architecture & Design World 2008
July 21 - 24, Hyatt Regency, Chicago, IL
http://www.sdexpo.com/2008/archdesign/maillist/mailing_list.htm
Linuxworld Conference
August 4 - 7, San Francisco, CA
http://www.linuxworldexpo.com/live/12/
VMware VMsafe protects VMsVMware has a new security technology called VMware VMsafe, http://www.vmware.com/go/vmsafe , that protects applications running in virtual machines in ways previously not possible in physical environments. The VMsafe APIs allow vendors to develop advanced security products that combat the latest generation of malware. VMsafe technology integrates into the VMware ESX hypervisor and provides the transparency to prevent threats and attacks such as viruses, trojans, and keyloggers from ever reaching a virtual machine.
Twenty security vendors have embraced VMsafe technology, and are building products that will further enhance the security of virtual machines, making the virtual environment unmatched in the level of security and protection it provides compared to physical systems.
VMsafe technology integrates at the hypervisor layer of virtualization to detect and eliminate the latest generation of malware. The VMware hypervisor is an ultra-thin layer of software that runs directly on server hardware independently of the operating system, enabling users to create virtual machines on the server in which to run applications. VMsafe technology provides transparency into the memory, CPU, disk, and I/O systems of the virtual machine, and monitors every aspect of the execution of the system. Security products built on VMsafe technology are able to stop malware before it harms a machine or steals data, including the latest generation of rootkits, trojans, and viruses, which are undetectable on physical machines.
HP offers Linux Support for SMB MarketOn March 31st, HP will introduce a new version of HP Insight Control Environment for Linux (ICE-Linux), a solution that enables midsize businesses to manage growing Linux server and cluster environments. Built on the HP Systems Insight Manager (SIM) infrastructure, ICE-Linux provides a single point of control for tying Linux server and cluster environments to an organization's broader data center. It simplifies discovery, imaging, monitoring, and management for Linux-based HP ProLiant server platforms.
HP is also introducing HP Linux Oracle Quick Reference Solutions, pre-sized configurations of HP and Oracle database components for Linux-based HP ProLiant servers. The solutions save midsize businesses a significant amount of time and money, from initial deployment through ongoing maintenance of a CRM solution.
From more info, go to http://www.hp.com/linux .
Vendor/ISV Announcements from EclipseCon
AccuRev Inc. announced its new Eclipse plug-in with management
functionality directly within their Eclipse IDE. These included full
support for the Eclipse Team Synchronize View, Eclipse History View, and
enhanced diff and merge functionality, including namespace merge
functionality in the Team Synchronize View.
http://www.accurev.com
CodeGear announced it has teamed with Instantiations, Inc., to integrate
Instantiations Swing Designer visual layout tools into CodeGear
JBuilder. Java developers using JBuilder will now be able to construct
more sophisticated and reliable Swing-based GUIs for enterprise
applications.
http://www.codegear.com/article/37695
CodeGear announced it has funded the contribution of a new
fast Ruby debugger to Eclipse Dynamic Language Toolkit. The debugger includes
stepping, run to breakpoint, smart step, variable introspection, hot
swap, remote debugging, and a free-form expression analyzer. CodeGear
3rdRail 1.1 includes the fast debugger in addition to full support for
Rails 2.0, refactorings, and conversion tools to migrate applications to
Rails 2.x.
http://www.codegear.com/products/3rdrail
Genuitec released two major products at EclipseCon: Pulse 2.0, an
Eclipse-based provisioning tool and MyEclipse 6.1 Blue Edition, a custom
toolsuite for WebSphere and RAD users. Both products originated from
customer demand and provide massive productivity increases for processes
and expanded feature sets.
http://www.myeclipseide.com
http://www.poweredbypulse.com
IBM announced that its Jazz technology platform is helping students
learn how to collaborate on global software development projects. Every
year, IBM awards universities with grants allowing the next generation of
developers to research software development team collaboration on a
global scale.
http://www.ibm.com/software/rational/jazz/
ILOG introduces Agile Business Rules Development (ABRD) methodology, the
industry's first free, vendor-neutral step-by-step methodology for
developing business rule applications. The company also donated an open
source Java to C# source code converter, and is spearheading the Albireo
project for developing Rich Client Platform applications.
http://www.ilog.com/corporate/releases/index.cfm
Innoopract, provider of the popular Yoxos Eclipse distribution announced
the availability of a new Software-as-a Service offering for managing
Eclipse and team collaboration. Yoxos Hosted Edition is a simple to use
software service that enables professional development teams to
collaborate and share project environments, including Eclipse toolsets,
configurations, and source code.
http://www.innoopract.com/en/news-events/news-press-releases/article/yoxos-hosted.html
Instantiations's newly enhanced CodePro AnalytiX Server now offers modern,
agile and innovative software analysis tools for use in mainstream
development organizations. It automates Java code auditing, metrics,
code coverage, JUnit test results, and reports through a new management
dashboard. It integrates into automated build systems using Ant or Maven,
and returns actionable results to both developers and managers,
automatically.
http://www.instantiations.com/press/release/080317.html
Klocwork, Inc. announced support for Carbide.c++, a family of
Eclipse-based development tools supporting Symbian OS development on the
S60 platform, the Series 80 platform, UIQ, and MOAP.
http://www.klocwork.com/company/releases/KlocworkAnnounceSupportForCarbide.asp
OpenMake Meister 7.2 will enhance the continuous integration process for
Eclipse developers. Meister 7.2, release scheduled for May, includes the
ability to automatically mashup the developer's Eclipse IDE build with
the Continuous Integration build running outside of Eclipse, preventing
broken builds caused by source code changes that adversely affect the build
scripts.
http://www.openmakesoftware.com/press-releases/
Protecode has developed the first automated preventative Intellectual
Property management solution. The software plug-in unobtrusively manages
IP by detecting 100% of external content, then logging, identifying, and
reporting pedigree during any stage of a software development project.
"Protecoding" automatically creates a software Bill of Materials,
offering a clean pedigree that insures accurate use of licenses.
http://www.protecode.com
Replay Solutions has trial downloads of new product ReplayDIRECTOR for
Java EE, a unique record and replay technology with an Eclipse plug-in.
ReplayDIRECTOR captures and re-executes java applications allowing
developers, QA, and production teams to easily and without the original
issue infrastructure, reproduce non-reproducible bugs.
http://www.replaysolutions.com/news/news.php?id=29
Skyway Software announced that Skyway Visual Perspectives offers unique
Eclipse plug-in capabilities for Spring. With Skyway Visual
Perspectives, developers can now model their entire solution (including
data structures, business logic, and rich user-interfaces) or simply
switch views and code whatever they need, whenever necessary. Read more
at
http://www.skywayperspectives.org.
http://www.skywaysoftware.com/lp/eclipsecon2008.php
SlickEdit, Inc., provider of the most advanced code editors available,
announces the release of SlickEdit's newest product, SlickEdit Core v3.3
for Eclipse. This version is for Eclipse 3.3 and CDT 4.0. SlickEdit Core
is a plug-in for Eclipse that allows developers to use the popular
SlickEdit code editor as the default editor within the Eclipse
environment. SlickEdit Core consists of the SlickEdit editor, 7
additional views, and the DIFFzilla® differencing engine. Together,
this functionality offers developers greater editing power and better
speed in navigating code, allowing even the most accomplished power
programmers to be more productive.
http://www.slickedit.com/content/view/482/237/
SpringSource announced the availability of the SpringSource Tool Suite,
which builds on the success of Eclipse, Mylyn, and Spring IDE. It
simplifies development of Spring-powered enterprise Java applications,
dramatically reduces information overload and aggregates the best
practices established by SpringSource consultants and the Spring
community. To download, please visit
http://www.springsource.com/products/sts.
http://www.springsource.com
Teamprise announced the availability of Teamprise 3.0, its latest
release of client applications providing Java and cross-platform
development teams with full access to the application lifecycle
management features of Visual Studio 2008 Team Foundation Server.
Demonstrations were being given by Teamprise and Microsoft, while
co-exhibiting at EclipseCon 2008.
http://www.teamprise.com
Virtutech, Inc., the leader in Virtualized Software Development (VSD),
announced an initiative to accelerate the creation of standards for the
VSD industry and to drive mainstream acceptance of VSD throughout the
electronic systems business. Virtutech intends to leverage its expertise
to propose, promote and support best practices, conventions, and
standards for VSD.
http://www.businesswire.com/portal/site/google/?ndmViewId=news_view&newsId=20080310005300&newsLang=en
Talkback: Discuss this article with The Answer Gang
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.


Kat likes to tell people she's one of the youngest people to have learned to program using punchcards on a mainframe (back in '83); but the truth is that since then, despite many hours in front of various computer screens, she's a computer user rather than a computer programmer.
Her transition away from other OSes started with the design of a massively multilingual wedding invitation.
When away from the keyboard, her hands have been found wielding of knitting needles, various pens, henna, red-hot welding tools, upholsterer's shears, and a pneumatic scaler. More often these days, she's occupied with managing her latest project.
PostgreSQL - "The world's most advanced open source database" as stated at http://www.postgresql.org/ - is packed with features that can help you immensely when developing applications. In this series, we will see three very important, often under-utilized options that have a broad range of uses. They are called Views, Stored Procedures, and Triggers.
We will use real-world examples, with lots of code to help you understand those features.
A View is a pre-selection of data that can be accessed by an SQL query. It minimizes the need for complex (sometimes very complex) SQL in your application and is often used to retrieve data for standard reports or other regularly-fetched data sets.
As an example, let's assume that you have the following tables in your database (you can use these SQL commands to create your own test suite):
create table cpu ( cpu_id serial primary key, cpu_type text ); create table video ( video_id serial primary key, video_type text ); create table computer ( computer_id serial primary key, computer_ram integer, cpu_id integer references cpu(cpu_id), video_id integer references video(video_id) );
And the following data inside it:
insert into cpu(cpu_type) values('Intel P4 Dual Core D');
insert into cpu(cpu_type) values('AMD Athlon');
insert into video(video_type) values('Geforce 8600GT');
insert into video(video_type) values('Radeon 9550');
insert into computer values (0, 512, 1, 2);
insert into computer values (1, 1024, 2, 1);
insert into computer values (2, 512, 2, 2);
That's a pretty simple database with 3 tables - CPUs, video types, and computers, tied up with Foreign Keys. Now let's say you need to fetch the computer data from those tables - but you don't want the CPU and Video IDs, just the description. You can use the following SQL:
select a.computer_id, a.computer_ram, b.cpu_type, c.video_type from computer a, cpu b, video c where (a.cpu_id=b.cpu_id) AND (a.video_id=c.video_id);
That will return the following:
0 512 "Intel P4 Dual Core D" "Radeon 9550" 1 1024 "AMD Athlon" "Geforce 8600GT" 2 512 "AMD Athlon" "Radeon 9550"
Now if you use that same SQL a lot, you can simplify calling it by defining a view, like this:
create or replace view computer_full(computer_id, computer_ram, cpu_type, video_type) as ( select a.computer_id, a.computer_ram, b.cpu_type, c.video_type from computer a, cpu b, video c where (a.cpu_id=b.cpu_id) AND (a.video_id=c.video_id) );
That's "create [or replace] view (view name) [(returned field aliases)]
as (sql)". The "or replace" is useful for testing: it
replaces the view if it already exists, so you don't need to DROP it
before re-creating. The field aliases are optional, and if omitted the
view will return the field names.
Now anywhere you need that same data, you can have it by executing
select * from computer_full;
The result will be the same we have above. You can even use WHERE clauses too, like:
Select * from computer_full where computer_id=1
The result will be:
1 1024 "AMD Athlon" "Geforce 8600GT"
That helps, not only by simplifying your queries, but also makes it easier in case you find a bug on your code, or a better way to do it - you simply change the View, and in every place that you called it, the new code will be executed. Let's change our view to a more professional way of selecting data - junctions. Junctions are a better way of fetching data from multiple tables, being faster than the labeling tables method we used above. There's several ways of doing junctions, and on our example we can choose between 2 of them:
create or replace view computer_full as ( select computer_id, computer_ram, cpu_type, video_type from computer a right join cpu b on (a.cpu_id=b.cpu_id) right join video c on (a.video_id=c.video_id) );
and
create or replace view computer_full as ( select computer_id, computer_ram, cpu_type, video_type from computer natural right join cpu natural right join video );
The first option, using "on" is used when the Column name you are using to connect the two tables are different ('on computer_cpu_id=cpu_id'), and the second one (natural join) is used when both column names are identical. That's the reason we had to label our tables (computer a, cpu b, video c) in our first example - using 'on cpu_id=cpu_id' would be ambiguous. Try to always use Natural Joins whenever possible - they are easier to understand and usually faster.
Temporary ViewsTemporary Views are, just as the name says, temporary views. You can use then just like views, but they are not supposed to be static (i.e., always in your database.) A quick example of a temp view is:
create temp view products (model, price) as select model, price from pc union select model, price from laptop union select model, price from printer
and dispose of it with
drop view test
Temporary views can be useful for storing the code of dynamic reports or similar tasks.
Views are more of a convenience than a speed feature, but using them can be helpful when developing systems.
There's a small .sql file attached to this article - if you open it in PGAdmin, there's code to create test data for our sample tables (50000 CPUs and Videos, 500000 computers). You can use it to see how Views and normal SQL commands behave, speed- wise, with a large dataset.
Well, that's it for this article, I hope it was useful - next month, we'll cover Stored Procedures!
A special thanks goes out to teacher Saulo Benvenutti, great Database teacher - it was a pleasure to be in your classes.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/dokopnik.jpg)
Deividson was born in União da Vitória, PR, Brazil, on 14/04/1984. He became interested in computing when he was still a kid, and started to code when he was 12 years old. He is a graduate in Information Systems and is finishing his specialization in Networks and Web Development. He codes in several languages, including C/C++/C#, PHP, Visual Basic, Object Pascal and others.
Deividson works in Porto União's Town Hall as a Computer Technician, and specializes in Web and Desktop system development, and Database/Network Maintenance.
Lately, there have been a lot of conferences focusing on the role of digital identity and the role of Identity Management [IdMgt or IdM] technology. This is a strong indicator of the level of interest by a broad group of stakeholders: government, enterprise IT, SaaS and mobility service providers, security firms, Internet merchants and Web 2.0 site operators, privacy advocates, and large user communities.
The issues are still being scoped - but innovative and potentially disruptive technical solutions are already being developed by startups and niche players, and you'd need a scorecard to sort out the players and the issues. Opportunities for doing just that abound at conferences and interop events such as the annual RSA conference, the annual Digital ID conference, IT and government security events, and events put on by ACM and USENIX among others, and the pundit platforms provided by the Gartner Group and the Burton Group.
What we learn at these events is that under the newly enhanced regulatory environment, identity policy, provisioning, management, and lifecycle are critical for both security needs on the one hand and also for meeting legal and compliance requirements on the other. Government and industry alike know they have to address these points, but the ink hasn't dried on the standards or the expectations. Figuring out what to do is at least as important as how, but both areas are still being defined so there's a place for both the technical conferences addressed at implementers, and the conferences focusing on governance and management. Bring on the pundits, please.
It's also hard to ignore the David and Goliath comparisons. But maybe that's why you're reading this Away Mission. OK, let's get to it.
Featured Below:
RSA Confererence
Burton Catalyst vs. Gartner ITxpo
The complexities of Digital ID management have been the focus of many IT and security technology conferences over the past year. All have had to touch on ID federation and the relations between ID providers, ID authenticators and those relying on this information in digital transactions. All the major conferences have paid attention to the demands of user-centric ID mechanisms that afford a large measure of selection and control to the persons represented by these digital IDs.
Two trends have clearly emerged in the last year. First, user-centric ID is better understood and better supported by Web businesses, as shown by the acceptance of OpenID and other user-centric ID management technologies. Second, the Higgins framework for digital ID Federation and interoperability has also gained significant mind share and support and is now used in several shipping products.
OpenID has had a lot interoperability wins this last year and some 10,000 Web sites now allow login via OpenID. Although OpenID has many options, usually a URL associated with the user is accepted as an identity credential. Typically, this is a person's blog address. If a person blogs on multiple subjects, each URL is relevant to its particular subject.
Identity guru Kim Cameron said this about OpenID: "OpenID gives
us common identifiers for public personas that we can use across multiple
Web sites - and a way to prove that we really own them."
Cameron
goes on to call this a huge win compared with random screen names and a
hodge-podge of passwords.
OpenID 'news' is discussed further in the RSA section below.
Higgins, which began in 2003 and became an Eclipse incubator project in 2004, released its 1.0 version in February. Products from Serena and Novell (Bandit) now use Higgins code and abstractions and a larger community of developers is coalescing around it. Why? Because it provides a lot of needed functionality for transactions between ID providers and ID consumers and because of its broad, agnostic any-to-any approach.
Higgins has support for straight SAML protocols and also the SOA supported WS-Trust protocols. Higgins has plugins written in both C++ and Java, and Higgins supports the InfoCard concepts derived from (but not limited to) Microsoft's CardSpace. In short, Higgins is the right intermediary framework for this IdMgt epoch.
Higgins is currently in use by ALF, CloudTripper.org and the Community Dictionary Service. The Novell DigitalMe product is over 90% Higgins-based.
The Higgins community is also working on notation for graphing ID relationships and correlations of the same person, something very important to usefulness of social and business networks. Higgins borrows here from Semantic Technology, using descriptive tuples in a manner like RDF and OWL. This is currently called Higgins OWL or H-OWL. Discussions on this and the data model should appear here:
http://wiki.eclipse.org/Higgins_Data_Model
The Higgins Project will be demonstrating Release 1.0 at the user-centric identity interoperability event at RSA2008. The last major use interop event in the US took place at the June 2007 Burton Catalst conference.
IBM, Novell, Parity and other vendors will all be showing interoperable applications based on the Higgins framework. This event will feature interoperability between identity providers, card selectors, browsers and Web sites. When users 'click-in' to sites via managed information cards, or i-cards, components from Open ID, Higgins Identity Framework, Microsoft CardSpace, SAML, WS-Trust, Kerberos and X.509 will hopefully interoperate within an identity layer built from both open-source and commercial components. Card selectors can be embedded in Mozilla browsers, or based on the GTK/Cocoa selector for BSD and Linux.
The less ambitious demo in 2007 worked well after all the servers were up and initialized.
The Burton Catalyst conference, reviewed below, analyzed emerging trends in IdMgt and heavily featured user-centric ID solutions like OpenID and Higgins. With Higgin's leap from incubator status to production software, it will a lot more pervasive.
The Goliath conference in the security realm would be the RSA conference. This Godfather of the modern security conference was originally a specialty conference for cryptographers and mathematicians 17 years back. Now, the conference is broadly focused on security issues and security products, and features big tech company CEO keynotes along with occasional keynotes by researchers and a huge vendor expo. For a while, the RSA conference was held in San Jose, but more recently has been resident in San Francisco.
I recall attending when it was an insider's conference, a kind of united white hats parley to discuss cutting edge research. When enterprises realized that multiple layers of security were de rigueur, the big dollars started to be made in security, and the RSA conference became a necessary venue for security firms and the big software houses. Then they were bought by EMC, which broadened the conference to include secure storage. They still call the big conference party "The Cryptographers Ball" and host a separate researchers track that requires serious credentials to join.
The company behind the initials - and the crypto algorithm that also bears the same initials - has stood for cryptographically secure products for the same time period. Arguably, the RSA algorithm, now in the public domain, has been instrumental in allowing allowing secure Web traffic and internet commerce to occur. (The initials stand for Ron Rivest, Adi Shamir and Len Adleman, who invented the RSA algorithm in 1977 (RIVE78)).
This is where a lot of security products - and partnerships - get announced and where the big companies try to explain initiatives they are only just starting. In 2007, attendess heard from Intel, Cisco and Oracle, as well as EMC. Futurist Ray Kurzweil gave the closing keynote on technological progress and evolution. For the RSA 2008 conference, there will be speakers from CA, IBM, Microsoft, and smaller ISVs like TippingPoint and Websense. There will also be a special keynote by Al Gore on "Emerging Green Technologies" on April 11th. Here's a list of all the RSA 2008 keynotes: http://www.rsaconference.com/2008/US/Conference_Program/Keynote_Speakers.aspx
All the keynote presentations from RSA 2007 are available here: http://media.omediaweb.com/rsa2007/index.htm
One of the most far-reaching announcements at RSA 2007 was Bill Gates's keynote, where he said that Microsoft would support and collaborate with the OpenID project. This led to Microsoft, IBM, Google, Yahoo, and Verisign joining the OpenID Foundation as corporate board members this past February. The OpenID Foundation was formed in June 2007 to support and promote the technology developed by the OpenID community.
OpenID enables individuals to convert one of their already existing digital identifiers -- such as their personal blog's URL -- into an OpenID account, which then can be used as a login at any Web site supporting OpenID.
Most of the content for RSA 2007 is accessible only with the conference CD. However, a very nice selection of "Expert Tracks" were videoed and are available publicly online. I would recommend the sessions on ID federation and also session 202 - "Deeper Injections: Command Injection Attacks Beyond SQL". Find that material here: http://media.omediaweb.com/rsa2007/tracks/index.htm
Another item available on the Web is Pat Peterson's presentation on "Deconstructing a 20-billion Message Spam Attack" from 100,000 zombie bots. (Patrick Peterson is Vice President of Technology at IronPort Systems.) That's available here: https://www.eventbuilder.com/event_desc.asp?p_event=w5b6g9q1
Although an Expo/Keynote pass to RSA 2008 is not free, many participating vendors email discount codes for free expo admission. You can contact the ones you are familiar with or, if you have contact with Applied Identity, or would like to, use code EXP08APP before April 4, 2008.
If you are interested in my conference review of RSA 2005, just click here: http://linuxgazette.net/112/dyckoff.html
Gartner is subscribed to by almost all of the Fortune 1000. It bought out META Group a couple of years back, and the Cambridge Group as well as other small fish in the consulting business. It's the 800-pound, or maybe 8000-pound, consultancy. Its researchers maintain over 20 distinct advisory services and each of those holds annual conferences. If your company subscribes to Gartner services, some annointed co-workers get to go to some of these. It's also hard to ignore Gartner pronouncements, especially since they have the ear of many C-Level executives.
Gartner does a lot of research so it's wise to pay attention. Gartner, and its competitors, are good at spotting and analyzing industry trends early. They tend to follow the major vendors in each sector closely, and may ignore an upstart, particularly in the open source arena, due to this focus. However, Gartner also tries to link in their other services and there is a bit of cross-selling going on.
The major challengers to Gartner are the Burton Group and Forrester Research. Both offer significant access to webinars and white papers on-line, a substantial number of these for free. The Burton Catalyst conference is aimed at IT innovators and bleeding edge adopters, as well as those trying to gauge the velocity of change. The purpose of the conference is to make sense of leading IT issues and trends both individually and as a group, and this conference - unlike the more narrow focus of the Gartner events - often draws experts from all of their research services, and high value guests from outside institutions and communities. Many of the key Burton presenters blog regularly on their research areas and also use reader comments to prepare the prepare for upcoming events.
I like both events but I have to express a preference for the size, the mix, and the medley of Burton Catalyst. Because the events are smaller, it's easier to find people interested in networking; and because of the interlinking, one gets more of a 3D view of issues and architectural approaches. Bottom line: I feel like I learned and understood more at the end of the Catalyst Conference than after a Gartner Group IT Security conference in 2007.
Having said that, I note that both organizations make getting the conference materials difficult if your company does not subscribe to a consulting service. Burton was better here, with most materials going up 2-3 weeks after the conference for a download window of about 6 weeks. I had trouble for the 2006 Catalyst Conference since the materials were unavailable for the first 10 days after the conference and I checked back about 60 days afterward, only to find out the download window had closed. (They did provide some individual presentations on request.) Communications from Burton was much better in 2007 and it was easier to know when the window would open and close. Burton also provided live downloads during the conference but most of the last day's presentations were not available on that day. No conference CD was available, but some vendors provided USB drives. All that was required was a conference login, with an online option for forgotten passwords.
Gartner, in contrast, did provide a conference CD, but many of the sessions were either missing or had only a short text outline. The missing or incomplete presentations were not available during the conference. Getting the materials afterward required the conference CD and a Gartner account key, which attendees did get but had to be hunted for. I think Gartner should have kept conference attendees better informed about the availability of late posted presentations, but I also know that this is a general problem for IT, developer, and other technical conferences. Since both Gartner and Burton are in the business of selling their research, the extra barriers are understandable but can more than a little annoying.
On the swag and party level, Burton also wins but only by a nose. Gartner gave attendees a real day backpack with a pocket for laptops while Burton handed out small padded zipper bags that are great for slipping inside other bags (like the Gartner bag).That's a point for GGrp. And Gartner had a real vendor expo, which partly conflicted with the schedule of presentations. Burton Catalyst has a tradition of evening vendor soirees along two corridors of hotel ballrooms and meeting rooms. Every room has a theme or game and each has either food or drink or both plus marketing swag. Some contests included iPods or LCD TVs; for example SAP gave out 2 GB USB jump drives for asking technical questions about their IdMgt products. But the major point here is that the vendor presentations were evening affairs, outside of conference hours, and easily accessible. (One vendor couldn't get the space needed one night, so their event was held directly across the street and started half and hour before the other events - see, very easy.)
The main thrust of the 2007 GGrp IT Xpo was the need to innovate and provide greater value for the enterprise. This meant assembling a creative mix of available technologies and allowing individual workgroups and departments to experiment. Corporate attitudes toward consumer tech entering the enterprise must shift from "unavoidable nuisance" to "opportunity for additional innovation". It also means rethinking the IT Fortress mentality. One of the key ways to achieving this more open state is to begin to use ID provisioning, ID federation, and ID management.
"Most IT organizations simply cannot deliver new value, new processes,
new markets, and new channels because their DNA is fundamentally about
control, which is the opposite of what you need for innovation and
growth,"
said Jennifer Beck, group vice president at Gartner.
Gartner also said that about 30 percent of IT funding is not going to
centralized functions, but into the business units, such as sales and
marketing, for their own research and development. In June of 2007,
Jackie Fenn, vice president and Gartner fellow, said, "By embracing and
leveraging employee experimentation and experience with consumer
technologies, enterprises can enjoy a significant addition to the
resources they can apply to evaluating innovation."
A recent Gartner survey found that most organizations have work underway to develop a strategy for Web 2.0, but few are prepared for, or executing on that strategy. Gartner predicted that by year-end 2007, about 30 percent of large companies will have some form of Web-2.0-enabled business initiative under way.
The internal challenge for companies experimenting with Web 2.0 is characterized by inbound risks, such as malicious code in RSS feeds, and outbound risks, such as information leakage through inappropriate blogging or use of collaboration tools. The external challenge is threats generated by enterprise usage and participation in Web 2.0 technologies, such as use of third-party content (mashups) and engaging in open user communities.
At Burton Catalyst, I kept mostly to the IdMgt and Security tracks, which occassionally conflicted. There were other tracks on Networks, SOA, Computer OSes, and Data Center Operations. One of the key takeaways was that current IdM products actually reinforce the traditions of centralized control to achieve provisioning, federation, and de-provisioning. This counters and undermines distributed processing, departmental independence, user-centricism, etc., and also runs counter to the Web 2.0 trend.
Although a lot was said about ID management and federation, about credentials and role-based security, a Feb 15 entry at identityblog.burton.com by analyst Gerry Gebel provides a good summary of how Burton understands the current era:
"Technologies like federation help us make incremental advancements
beyond the command and control approach. If we permit authentication to
occur outside our domain and project this information through a
federation exchange, that's a sign of progress. However, federation
products, as they are currently constructed, still require considerable
coordination between parties in order to establish the connection: we
focused on this issue at Catalyst last year.
"So, it was interesting to see the recent video sparring between Sun
and Ping
Identity regarding what they've done to address this from a technology
perspective. To follow up, we recorded a podcast this week with Sun, Ping
Identity, and Covisint - which will be available soon on the podcast
site .
"More incremental change is what we can expect in the near term until
different identity business models emerge. Similarly, the introduction
of OpenID and information card systems purport to change the dynamic by
providing more user control over identity data, but this is in name only
- business still determine what attributes are required to complete an
e-commerce transaction and the user can select an information card that
matches the business' criteria. Real change happens when third party
identity agencies and intermediaries proliferate and are utilized by
Internet properties. Identity oracles, as described here, are examples
of intermediaries that are beginning to appear in the marketplace."
Don't forget to visit Burton's analyst's blogs home page to get the
Burton skinny on all their major research areas:
http://www.burtongroup.com/Guest/BurtonGroupBlogs.aspx
From the October IT Xpo in Orlando, here are the top 10 trends as GGrp
see it between now and 2010:
The Gartner Emerging Trends Symposium/ITxpo 2008
will be held April 6-10, in Las Vegas. Gartner Group will host their
main IT Security conference in Washington DC, June 2-4, 2008: Gartner IT Security Summit
Here's a link to their Web site on Security topics:
http://gartnergroup.com/it/products/research/asset_129509_2395.jsp
This year, Burton Catalyst will be held over 5 days in June in San Diego,
instead of San Francisco. Information is
here. [http://www.catalyst.burtongroup.com/na08/ ]
Forrester's IT Forum 2008 will lead both GGrp and Burton by taking place May 20-23 in Las Vegas:
http://www.forrester.com/events/eventdetail?eventID=2067
Next time we will discuss the annual Digital ID World conference.
Talkback: Discuss this article with The Answer Gang
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.
Creating your own Virtual Private Network (VPN) is quite easy on platforms that come with a tun driver: this will allow you to process network packet traffic in user space. While that's considerably easier than doing your network programming in the kernel space, there still are a few details to figure out. This article should walk you through my findings.
The tun driver is a two-in-one device:
This article discusses code written around the Ethernet device. If you choose the IP driver, then you will generate about 18 bytes per packet processed less traffic (the Ethernet header and trailer) but you will have to code a bit more to setup your network.
First, we have to make sure the tun driver is active. On my Debian system, I simply have to load it:
# /sbin/modprobe tun # /sbin/lsmod | grep tun tun 10208 0 # /bin/ls -l /dev/net/tun crw-rw-rw- 1 root root 10, 200 2008-02-10 11:30 /dev/net/tun
For demo purposes, we will build a virtual network of two hosts. Once we have our hands on the Ethernet frames, we will use UDP encapsulation to transmit them from a virtual interface on host A to the virtual interface of host B and vice-versa.The UDP socket will be used un-connected; this has the advantage of using the same socket to send and receive packets from any other host in our virtual network. However, the un-connected nature of our UDP socket raises some difficulties in getting the path MTU (more on this below).
Each host in our virtual network will run an instance of the demo program. To illustrate it, the traffic from an application (here telnet) on host A to its corresponding application (inetd/telnetd) on host B will take the following path:
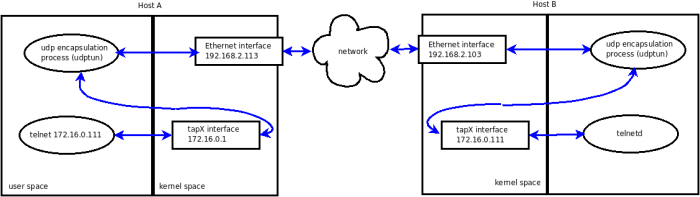
In practice, we need a mechanism to map virtual IP addresses to real IP addresses. It is up to us to brew up some discovery method to resolve this mapping issue - but since this is not relevant to our topic, or for the purpose of our little demo described here, we'll cheat and pass the "map" to the tunneling program through command line parameters:
Host A# ./udptun
Usage: ./udptun local-tun-ip remote-physical-ip
Host A# ./udptun 172.16.0.1 192.168.2.103
Host B# ./udptun 172.16.0.111 192.168.2.113
The first thing we need is to create a virtual Ethernet (tap) interface. This is done with a simple open() call:
struct ifreq ifr_tun;
int fd;
if ((fd = open("/dev/net/tun", O_RDWR)) < 0) {
/*Process error, return.*/;
}
memset( &ifr_tun, 0, sizeof(ifr_tun) );
ifr_tun.ifr_flags = IFF_TAP | IFF_NO_PI;
if ((ioctl(fd, TUNSETIFF, (void *)&ifr_tun)) < 0) {
/*Process error, return.*/;
}
/*Configure the interface: set IP, MTU, etc*/
Here, the flag IFF_NO_PI requests that we manipulate raw frames. If not set, the frames will be prepended with a 4 bytes header.
The virtual interface needs to be identified by an IP address. An ioctl() call will set it:
/* set the IP of this end point of tunnel */
int set_ip(struct ifreq *ifr_tun, unsigned long ip4)
{
struct sockaddr_in addr;
int sock = -1;
sock = socket(AF_INET, SOCK_DGRAM, 0);
if (sock < 0) {
/*Process error, return*/
}
memset(&addr, 0, sizeof(addr));
addr.sin_addr.s_addr = ip; /*network byte order*/
addr.sin_family = AF_INET;
memcpy(&ifr_tun->ifr_addr, &addr, sizeof(struct sockaddr));
if (ioctl(sock, SIOCSIFADDR, ifr_tun) < 0) {
/*Process error, return*/
}
/*Will be used later to set MTU.*/
return sock;
}
The only other thing we have to set is the MTU (Maximum Transmit Unit) of the interface. For our pseudo-Ethernet interface, the MTU is largest payload that the Ethernet frames will carry. We will set the MTU based on the PMTU.
Simply stated, the PMTU is the largest packet size that can traverse the path from your host to its destination host without suffering fragmentation.
The PMTU is an important setting to get right. Consider this: upon (re)injecting your frames to the kernel, they will get a new set of headers (IP, UDP and Ethernet). Thus, if the size of the frame you send to the kernel is too close to the PMTU, the final frame that will be sent out of the real interface might be bigger than the PMTU. At worst, such a frame will be discarded somewhere "en route". At best, the frame will be split in two fragments and will generate a 100% processing overhead and some supplementary traffic.
To avoid this, we have to discover what the PMTU value is and ensure that the new Ethernet frame will be appropriately sized for the PMTU. Thus, we will subtract from the PMTU the overhead of the new set of headers and set the MTU of the virtual interface to this value.
With Linux, for a TCP socket, the task it easy: we just have to make sure the kernel mechanisms for PMTU discovery are set and we are done.
For UDP sockets though, we the users have the responsibility of ensuring the UDP datagrams are of proper size. If the UDP socket is connected to your correspondent host, a simple getsockopt() call with the IP_MTU flag set will give us the PMTU.
For unconnected sockets though, we have to probe the PMTU. First, the socket has to be set up so that datagrams are not fragmented (set the DF flag); then, we'll want to be notified of any ICMP error this might generate. If a host cannot handle the size of the datagram without fragmenting, then it will notify us accordingly (or so we hope):
int sock;
int on;
sock = socket(AF_INET, SOCK_DGRAM, 0);
if (sock < 0) {
/*Process error, return*/;
}
on = IP_PMTUDISC_DO;
if (setsockopt(sock, SOL_IP, IP_MTU_DISCOVER, &on, sizeof(on))) {
/*Process error, return*/;
}
on = 1;
if (setsockopt(sock, SOL_IP, IP_RECVERR, &on, sizeof(on))) {
/*Process error, return*/;
}
/*Use sock for PMTU discovery.*/
Next, we'll send out probe datagrams of various sizes:
int wrote = rsendto(sock, buf, len, 0,
(struct sockaddr*)target,
sizeof(struct sockaddr_in));
And finally, sift through the errors until we get the PMTU right. If we get a PMTU error, we adjust the datagram size accordingly and start sending again, until the destination is reached:
char sndbuf[VPN_MAX_MTU] = {0};
struct iovec iov;
struct msghdr msg;
struct cmsghdr *cmsg = NULL;
struct sock_extended_err *err = NULL;
struct sockaddr_in addr;
int res;
int mtu;
if (recv(sock, sndbuf, sizeof(sndbuf), MSG_DONTWAIT) > 0) {
/* Reply received. Enf of the PMTU discovery. Return.*/
}
msg.msg_name = (unsigned char*)&addr;
msg.msg_namelen = sizeof(addr);
msg.msg_iov = &iov;
msg.msg_iovlen = 1;
msg.msg_flags = 0;
msg.msg_control = cbuf;
msg.msg_controllen = sizeof(cbuf);
res = recvmsg(sock, &msg, MSG_ERRQUEUE);
if (res < 0) {
if (errno != EAGAIN)
perror("recvmsg");
/*Nothing for now, return.*/
}
for (cmsg = CMSG_FIRSTHDR(&msg); cmsg; cmsg = CMSG_NXTHDR(&msg, cmsg)) {
if (cmsg->cmsg_level == SOL_IP) {
if (cmsg->cmsg_type == IP_RECVERR) {
err = (struct sock_extended_err *) CMSG_DATA(cmsg);
}
}
}
if (err == NULL) {
/*PMTU discovery: no info yet. Return for now but keep probing.*/
}
mtu = 0;
switch (err->ee_errno) {
...
case EMSGSIZE:
debug(" EMSGSIZE pmtu %d\n", err->ee_info);
mtu = err->ee_info;
break;
...
} /*end switch*/
return mtu; /*But keep probing until remote host reached!*/
One last note: the PMTU is bound to change over time. Therefore, you'll have to retest once in a while, then set the MTU of the virtual interface accordingly. If you want to avoid this dance, you can set the MTU the "safe" but sub-optimal way: to the lesser of 576 and the MTU of the physical interface (minus the overhead we mentioned, of course.)
And finally, having this magic PMTU value, we can set the MTU of our virtual interface correctly:
struct ifreq *ifr_tun;
...
ifr_tun->ifr_mtu = mtu;
if (ioctl(sock, SIOCSIFMTU, ifr_tun) < 0) {
/*Process error*/
}
Now we have the virtual interface up and configured properly. All we have to do is to relay frames in both directions. First, open an un-connected UDP socket (I will spare you the details), then:
char buf[VPN_MAX_MTU] = {0};
struct sockaddr_in cliaddr = {0};
int recvlen = -1;
socklen_t clilen = sizeof(cliaddr);
recvlen = read(_tun_fd, buf, sizeof(buf));
if (recvlen > 0)
sendto(_udp_fd, buf, recvlen, 0, (struct sockaddr*)&cliaddr, clilen);
Caveat: read()ing from the tap file descriptor will block
solid. What this means is that the read() call will not be interrupted in the
eventuality you close the underlying file descriptor. This forces you to
poll()/select() this file descriptor before read()ing from if you want
to terminate this thread cleanly.
recvlen = recvfrom(_udp_fd, buf, sizeof(buf), 0,
(struct sockaddr*)&cliaddr, &clilen);
if (recvlen > 0)
write(_tun_fd, buf, recvlen);
Note that, in practice, if you have more than two hosts in your virtual network, you will have to look inside the frames for the source and destination IPs before deciding where to relay the frame.
You can download the full source for udptun.c, ttools.c, ttools.h and pathmtu.c along with the Makefile directly; all of the above are also available as a single tarball.
Since you have full control over the traffic of the virtual network, you could encrypt it in user space. For the purpose of this demo, to build a complete VPN, we will encrypt the traffic with IPSEC (note: IPSEC also has tunnelling functionality built in).
On Debian, just install the ipsec-tools package and use these files for manual keying:
For host A:
## Flush the SAD and SPD
flush;
spdflush;
# A & B
add 172.16.0.1 172.16.0.111 ah 15700 -A hmac-md5 "123456789.123456";
add 172.16.0.111 172.16.0.1 ah 24500 -A hmac-md5 "123456789.123456";
add 172.16.0.1 172.16.0.111 esp 15701 -E 3des-cbc "123456789.123456789.1234";
add 172.16.0.111 172.16.0.1 esp 24501 -E 3des-cbc "123456789.123456789.1234";
# A
spdadd 172.16.0.1 172.16.0.111 any -P out ipsec
esp/transport//require
ah/transport//require;
spdadd 172.16.0.111 172.16.0.1 any -P in ipsec
esp/transport//require
ah/transport//require;
For host B:
## Flush the SAD and SPD
flush;
spdflush;
# A & B
add 172.16.0.1 172.16.0.111 ah 15700 -A hmac-md5 "123456789.123456";
add 172.16.0.111 172.16.0.1 ah 24500 -A hmac-md5 "123456789.123456";
add 172.16.0.1 172.16.0.111 esp 15701 -E 3des-cbc
"123456789.123456789.1234";
add 172.16.0.111 172.16.0.1 esp 24501 -E 3des-cbc
"123456789.123456789.1234";
#dump ah;
#dump esp;
# B
spdadd 172.16.0.111 172.16.0.1 any -P out ipsec
esp/transport//require
ah/transport//require;
spdadd 172.16.0.1 172.16.0.111 any -P in ipsec
esp/transport//require
ah/transport//require;
Note how the whole encryption mechanism is tied to the virtual addresses, thus isolating you from the physical networks your hosts are on. You can download the ipsec-tools.conf directly.
It's show time! Let's ping the other host's virtual interface with a payload of 100 bytes:
Host A$ ping -s 100 172.16.0.111
And watch the traffic with tcpdump on the virtual interface:
#tcpdump -i tap0
...
15:43:27.739218 IP 172.16.0.1 > 172.16.0.111: AH(spi=0x00003d54,seq=0x1d):
ESP(spi=0x00003d55,seq=0x1d), length 128
15:43:27.740673 IP 172.16.0.111 > 172.16.0.1: AH(spi=0x00005fb4,seq=0x1d):
ESP(spi=0x00005fb5,seq=0x1d), length 128
15:43:28.738741 IP 172.16.0.1 > 172.16.0.111: AH(spi=0x00003d54,seq=0x1e):
ESP(spi=0x00003d55,seq=0x1e), length 128
15:43:28.740170 IP 172.16.0.111 > 172.16.0.1: AH(spi=0x00005fb4,seq=0x1e):
ESP(spi=0x00005fb5,seq=0x1e), length 128
15:43:39.494298 IP 172.16.0.1 > 172.16.0.111: AH(spi=0x00003d54,seq=0x1f):
ESP(spi=0x00003d55,seq=0x1f), length 64
15:43:39.496818 IP 172.16.0.111 > 172.16.0.1: AH(spi=0x00005fb4,seq=0x1f):
ESP(spi=0x00005fb5,seq=0x1f), length 40
On the physical interface:
# tcpdump -i eth2
...
15:45:46.878156 IP 192.168.40.128.11223 > 192.168.40.129.11223: UDP,
length 186
15:45:46.879021 IP 192.168.40.129.11223 > 192.168.40.128.11223: UDP,
length 186
15:45:47.879479 IP 192.168.40.128.11223 > 192.168.40.129.11223: UDP,
length 186
15:45:47.887054 IP 192.168.40.129.11223 > 192.168.40.128.11223: UDP,
length 186
15:45:48.880268 IP 192.168.40.128.11223 > 192.168.40.129.11223: UDP,
length 186
15:45:48.882738 IP 192.168.40.129.11223 > 192.168.40.128.11223: UDP,
length 186
All figures in bold are payloads. When it goes out of the virtual interface, the encrypted datagram is 186 bytes: 14 bytes the Ethernet header, 20 bytes the IP header, an AH header of 24 bytes, and ESP as the remaining 128 bytes.
When it goes out of the physical interface, the datagram is 232 bytes: 14 bytes for the Ethernet header, 20 bytes for the IP header, 8 for the UDP one, 186 bytes of payload and 4 bytes for the Ethernet trailer. Thus, we introduce a 46 byte overhead per datagram.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/melinte.jpg)
Aurelian is a software programmer by trade. Sometimes he programmed Windows, sometimes Linux and sometimes embedded systems. He discovered Linux in 1998 and enjoys using it ever since. He is currently settled with Debian.
Do you deal a lot with reading or writing text? Do you often use search tools? Do you have a pile of data sitting on your web and file server(s)? Many of us do. How do you organise your collection of text data? Do you use a directory, an index, or a database? In case you haven't decided yet, let me suggest a few options.
I will focus on organising, indexing, and searching text data. This is sufficient, since a lot of search queries can be transformed to text. In addition, processing text is harder than it seems, so it's good to have a focus. You may note that I make a distinction between documents and text data; the reason is the sheer volume of different document formats. Some of them are well-defined, some aren't. Some have open specifications readily available to developers. Proprietary document formats are always a barrier for data processing. Unfortunately, these formats cannot be avoided.
The first thing you have to do is to organise your data in some way. It doesn't matter if you populate a file server with a directory structure and start copying data or if you keep a list of bookmarks in your browser. The most important aspect is to have a kind of unique identifier or reference to every single document. Uniform Resource Locators (URLs) work well; a path to a file along with its name will also be perfect. It's best if you manage to group your documents by a list of categories. The next thing you have to consider is the document formats. Most indexing and search tools can only handle text, so if your document format allows for conversions, then it is useful for processing. Here are some examples for conversions done in shell scripts.
Keep in mind that although some converters can deal with MS Office documents, it is not the best format for storing information. The format is still proprietary and you may not use Microsoft's "free" document specification for any purpose (commercial use is explicitly excluded, therefore the specs are not free to use). Storing information in these formats will cause a lot of trouble - especially if the vendor disables old versions of the format by software updates (this has already happened). That's a clear and obvious warning, and if you have any word in how to organise document collections you can avoid a lot of trouble at the beginning.
Having thought about organising the data, we can now consider how to best index it. This doesn't mean that you are done with thinking about the organisation of the data - it really is the most important step.
MySQL offers the creation of full text indices; this is described in the manual in the "Natural Language Full-Text Searches" section. It is an easy way of indexing text data. Let's say you have the following table:
CREATE DATABASE textsearch;
USE textsearch;
CREATE TABLE documents (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
filename VARCHAR(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL,
path VARCHAR(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL,
type VARCHAR(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL,
mtime TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
content TEXT CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL,
FULLTEXT (filename),
FULLTEXT (content)
);
We'll store the filename, the path information, the file type, and its
converted content in a database table. The VARCHAR data type might
be too small if you have big directory trees, but it's more than enough for a
simple example. Every document has a unique ID consisting of the field
id. The option FULLTEXT() advises MySQL to create a full
text search index over the columns filename and content.
You can add more columns if you like, but you need to be careful not to
index everything. Adding the type column might also be a
reasonable option.
Now we need some content - so let's insert a few records for testing.
INSERT INTO documents ( filename, path, type, content ) VALUES ( 'gpl.txt', '/home/pfeiffer', 'Text', 'This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation;' ); INSERT INTO documents ( filename, path, type, content ) VALUES ( 'fortune.txt', '/home/pfeiffer', 'Text', 'It was all so different before everything changed.' ); INSERT INTO documents ( filename, path, type, content ) VALUES ( 'lorem.txt', '/home/pfeiffer', 'Text', 'Lorem ipsum dolor sit amet, consectetuer adipiscin...' );
Now you can do a full text search.
mysql> SELECT id,filename FROM documents WHERE MATCH(content) AGAINST('lorem');
+----+----------+
| id | filename |
+----+----------+
| 6 | test.txt |
+----+----------+
1 row in set (0.01 sec)
mysql>
The construct MATCH() AGAINST() does the full text search for you. MySQL uses a number to indicate the relevance of the table record. You can show all these rankings by querying for MATCH() AGAINST().
mysql> SELECT id, filename, MATCH(content) AGAINST('lorem') FROM documents;
+----+-------------+---------------------------------+
| id | filename | MATCH(content) AGAINST('lorem') |
+----+-------------+---------------------------------+
| 1 | gpl.txt | 0 |
| 2 | fortune.txt | 0 |
| 3 | s3.txt | 0 |
| 4 | s4.txt | 0 |
| 5 | miranda.txt | 0 |
| 6 | test.txt | 0.75862580537796 |
+----+-------------+---------------------------------+
6 rows in set (0.00 sec)
mysql>
Obviously, I added a few more rows than described originally. The right column displays the ranking. Only record 6 has a number greater than 0 because all the other texts lack the word lorem. Now you can add more texts and see what their rating is like. Note that MySQL uses a specific strategy when performing full text indexing:
Be careful - if your search query consists solely of stop words, you'll never get any results. If you need a full text search in languages other than English you can provide your own set of stop words. The documentation will tell you how to do this.
It is also possible to search for more than one word. You can add multiple words separated by commas.
SELECT id, filename, MATCH(content) AGAINST('lorem,ipsum') FROM documents;
Of course PostgreSQL can also deal with full text searches - a plugin called Tsearch2 is available for PostgreSQL database servers prior to version 8.3.0 (it's integrated into 8.3.0). Just like for the MySQL functions, you can fine-tune these according to the language your texts are written in. The content has to be transformed into tokens, and PostgreSQL offers new database objects that deal with these operations. The Tsearch2 engine provides text parsers for tokenisation, dictionaries for normalisation of tokens (and lists of stop words), templates for switching between parsers or dictionaries, and configurations to use whatever language you need to. Creating new database objects requires knowledge of C programming.
Let's recreate the example table in PostgreSQL (I use version 8.3.0; if you have an older version, please install Tsearch2):
CREATE TABLE documents (
id_documents serial,
filename character varying(254),
path character varying(254),
type character varying(254),
mtime timestamp with time zone,
content text );
CREATE INDEX documents_idx ON documents USING gin(to_tsvector('english',content));
First we create the table, then we create the text GIN (Generalized Inverted Index); this type of index consists of distinct lexemes. The function to_tsvector() converts the text stored in the content column into these normalised words. It uses the English parser and dictionary. Search queries look like this:
lynx=> SELECT filename,mtime FROM documents WHERE to_tsvector(content) @@ to_tsquery('lorem');
filename | mtime
-----------+------------------------------
lorem.txt | 2008-02-26 12:15:16.34584+01
(1 row)
lynx=>
You'd use a normal SELECT and the @@ text match operator. This operator compares arguments and the search string converted to lexemes by use of to_tsvector() and to_tsquery() functions. The results are returned by the SELECT statement. You can also use ranking in order to sort the results.
lynx=> SELECT filename,mtime,ts_rank(to_tsvector(content),to_tsquery('lorem'))
FROM documents WHERE to_tsvector(content) @@ to_tsquery('lorem');
filename | mtime | ts_rank
-----------+------------------------------+-----------
lorem.txt | 2008-02-26 12:15:16.34584+01 | 0.0607927
(1 row)
lynx=>
The tokenisation is one of the crucial parts of a text search, and it's important to understand the algorithms that Postgres uses to decompose a string. Consider the following example:
lynx=> SELECT alias, description, token FROM ts_debug('copy a complete database');
alias | description | token
-----------+-----------------+----------
asciiword | Word, all ASCII | copy
blank | Space symbols |
asciiword | Word, all ASCII | a
blank | Space symbols |
asciiword | Word, all ASCII | complete
blank | Space symbols |
asciiword | Word, all ASCII | database
(7 rows)
lynx=>
The example uses the ts_debug() function and shows every token with its classification. The text search module understands most of the common text constructs; it can also decode URLs.
lynx=> SELECT alias, description, token FROM ts_debug('http://linuxgazette.net/145/lg_tips.html');
alias | description | token
----------+---------------+-----------------------------------
protocol | Protocol head | http://
url | URL | linuxgazette.net/145/lg_tips.html
host | Host | linuxgazette.net
url_path | URL path | /145/lg_tips.html
(4 rows)
lynx=>
Now the parser displays the tokens as part of the URL and identifies them. The tokens allow for better search query processing, and this is the reason why you have to filter your query string. The text search compares tokens and not the strings themselves.
I presented only two ways to index text data. This is really only the tip of the iceberg - there's a lot more to learn about full text searches. Both MySQL and PostgreSQL have convenient algorithms ready for use that facilitate finding documents. You can use a simple Perl script with either one of these database engines, feed them your browser bookmarks and build an index with the content of the web pages, ready for search queries. There are many other tools available, and I'll present another way of indexing in the next part of this series. If you use something different or interesting to accomplish these tasks, please write and let us know about it!
Talkback: Discuss this article with The Answer Gang

René was born in the year of Atari's founding and the release of the game Pong. Since his early youth he started taking things apart to see how they work. He couldn't even pass construction sites without looking for electrical wires that might seem interesting. The interest in computing began when his grandfather bought him a 4-bit microcontroller with 256 byte RAM and a 4096 byte operating system, forcing him to learn assembler before any other language.
After finishing school he went to university in order to study physics. He then collected experiences with a C64, a C128, two Amigas, DEC's Ultrix, OpenVMS and finally GNU/Linux on a PC in 1997. He is using Linux since this day and still likes to take things apart und put them together again. Freedom of tinkering brought him close to the Free Software movement, where he puts some effort into the right to understand how things work. He is also involved with civil liberty groups focusing on digital rights.
Since 1999 he is offering his skills as a freelancer. His main activities include system/network administration, scripting and consulting. In 2001 he started to give lectures on computer security at the Technikum Wien. Apart from staring into computer monitors, inspecting hardware and talking to network equipment he is fond of scuba diving, writing, or photographing with his digital camera. He would like to have a go at storytelling and roleplaying again as soon as he finds some more spare time on his backup devices.
By Joey Prestia

Setting up disk quotas for users and groups is very important - critically necessary, in fact, if you don't want to run out of room on the server you are maintaining. They are commonly used for machines run as Web servers with ftp access, to prevent any one client from uploading beyond the amount of space that they have purchased in their contract. Disk quotas can also be used on Samba servers for users' home directories and NFS filesystems. Your Linux server can easily be configured to keep your users within specified limits and to keep them from filling up the partition. Some people will surf the Internet and download videos and mp3s carelessly during their lunch breaks, running other users out of space for their work files. To prevent this kind of activity, we set up user and group quotas to keep the users within boundaries.
Quotas are set on a per-partition basis, so, if we were going to set them up on a Web server (or NFS or Samba server), we need to find out if the area we are concerned with is on its own partition. In this tutorial, we will examine an ordinary setup with multiple users.
The first step is to find out if our home partition is on a separate partition - on most production servers, it is on its own partition (a dedicated partition). So, let's see what our partitioning looks like.
[root@station17 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda3 2.9G 205M 2.6G 8% / /dev/sda1 289M 17M 258M 6% /boot none 1013M 0 1013M 0% /dev/shm /dev/sda5 2.0G 36M 1.9G 2% /tmp /dev/sda2 9.7G 6.2G 3.1G 67% /usr /dev/sda7 2.0G 239M 1.6G 13% /var /dev/sda8 9.2G 54M 8.7G 1% /home [root@station17 ~]#
As you can see from the example above, /home is on a dedicated
partition. We now need to put the mount options into the filesystem table,
/etc/fstab, so whenever the system gets rebooted the quotas
are still active.
[root@station17 ~]# vi /etc/fstab # This file is edited by fstab-sync - see 'man fstab-sync' for details LABEL=/1 / ext3 defaults 1 1 LABEL=/boot /boot ext3 defaults 1 2 none /dev/pts devpts gid=5,mode=620 0 0 none /dev/shm tmpfs defaults 0 0 LABEL=/home /home ext3 defaults,usrquota,grpquota 1 2 none /proc proc defaults 0 0 none /sys sysfs defaults 0 0 LABEL=/tmp /tmp ext3 defaults 1 2 LABEL=/usr /usr ext3 defaults 1 2 LABEL=/var /var ext3 defaults 1 2 LABEL=SWAP-sda6 swap swap defaults 0 0 /dev/scd0 /media/cdrecorder auto pamconsole,exec,noauto,managed 0 0 [root@station17 ~]#
In the above example, you can see where I added usrquota and grpquota to
the mount options line, in fstab. Now, to enable use of these extra
options, we need to remount /home with these new options enabled.
[root@station17 ~]# mount -v -o remount /home /dev/sda8 on /home type ext3 (rw,usrquota,grpquota) [root@station17 ~]#
Here, we can see that /home has been remounted with the
additional options of user quotas and group quotas. Using the 'quotacheck'
command, we create our initial disk quota file. Once this command is run,
it will create two files located in the /home directory, named
aquota.user and aquota.group. They are binary
files that store our quotas. We will want to run it with '-cug' as the
command-line options: the 'c' is to perform a new scan and save it to disk,
the 'u' is for user, and 'g' stands for group. Then, we will turn quotas on
with the 'quotaon' command, specifying which partition we want to activate
quotas on.
[root@station17 ~]# quotacheck -cug /home [root@station17 ~]# quotaon /home [root@station17 ~]#
At this point, we can edit the users' quotas with the 'edquota' command. This will bring up the 'vi' editor, and we will see some columns that need a little explaining. The blocks represent the limits for soft and hard size quotas, and the inodes column is for a quota configuration based on the number of files a user may create. The soft limit may be exceeded for a defined grace period, but hitting the hard limit will stop a user dead.
Let's create a user and restrict them to a set of quotas, just to see just how this works. We'll add a user named "sally", and since she won't be logging in, we won't give her a password. Next, we will use the 'edquota' command to edit her quotas and give her some disk space limits - say, 10 MB soft and 12 MB hard - and write our changes.
[root@station17 ~]# useradd sally [root@station17 ~]# edquota sally Disk quotas for user sally (uid 502): Filesystem blocks soft hard inodes soft hard /dev/sda8 24 10000 12000 6 0 0 ~ ~
Now, sally has a 10MB soft and 12MB hard limit, so we want to switch to
that account and start creating some data. We can do this with the 'dd'
command and /dev/zero to see how this works. The 'dd' command
copies data at a low level, and we will use it here to create a file
quickly.
[root@station17 ~]# su - sally
[sally@station17 ~]$ dd if=/dev/zero of=data bs=1k count=9500
9500+0 records in
9500+0 records out
9728000 bytes (9.7 MB) copied, 0.0220105 s, 442 MB/s
[sally@station17 ~]$
[sally@station17 ~]$ quota
Disk quotas for user sally (uid 502):
Filesystem blocks quota limit grace files quota limit grace
/dev/sda8 9544 10000 12000 8 0 0
[sally@station17 ~]$
Here, sally checks her quota, and can see she still has more room to play, since no warning so far or anything else, so let's make some more data, and see if we get a warning.
[sally@station17 ~]$ dd if=/dev/zero of=moredata bs=1k count=500 sda8: warning, user block quota exceeded. 500+0 records in 500+0 records out 512000 bytes (512 kB) copied, 0.0034606 s, 148 MB/s [sally@station17 ~]$
This time, we get a warning. Let's see what our quota would look like if we were user sally.
[sally@station17 ~]$ quota
Disk quotas for user sally (uid 502):
Filesystem blocks quota limit grace files quota limit grace
/dev/sda8 10048* 10000 12000 7days 9 0 0
[sally@station17 ~]$
Looking at our quota file, we can see we have a grace period that has now come in to play. Sally has seven days to get under her limit. However, let's say that sally ignores this -- she doesn't care -- and creates another file, let's say 3MB, which would put us past our hard limit. Shall we see what happens?
[sally@station17 ~]$ dd if=/dev/zero of=file bs=1k count=3000
sda8: write failed, user block limit reached.
dd: writing `file': Disk quota exceeded
1949+0 records in
1948+0 records out
1994752 bytes (2.0 MB) copied, 0.0251631 s, 79.3 MB/s
[sally@station17 ~]$ quota
Disk quotas for user sally (uid 502):
Filesystem blocks quota limit grace files quota limit grace
/dev/sda8 12000* 10000 12000 10 0 0
[sally@station17 ~]$
We can see that sally wrote up to and past the soft limit, since she is given a grace period by default - but the hard limit stopped her careless activity cold. It's a good idea to get familiar with disk quotas, since they are very common in an enterprise environment, and you will most definitely run into them.
If you have, say, 15 users in a department that will all be working on the same project, a group quota would be in order. What if we had just 15 users who were in the same department, but working separately on different stuff, and were all supposed to get the same quota? We could use the 'edquota -up' command to copy sally's quotas to the other users. We could then use the 'repquota' command to see our users' imposed quota statistics. Let's add a couple of extra users and then try this out. Once again, we are not giving these users passwords, because this is just a demonstration.
[sally@station17 ~]$ su - Password: [root@station17 ~]# useradd tom [root@station17 ~]# useradd dick [root@station17 ~]# useradd harry
Now that we added some users, we can copy sally's quota to the new users on the system.
[root@station17 ~]# edquota -up sally tom harry
Here, we can verify that the users' quotas have been carried over to the users we selected on the system.
[root@station17 ~]# repquota -u /home
*** Report for user quotas on device /dev/sda8
Block grace time: 7days; Inode grace time: 7days
Block limits File limits
User used soft hard grace used soft hard grace
----------------------------------------------------------------------
root -- 69832 0 0 4 0 0
sally +- 11996 10000 12000 5days 10 0 0
tom -- 48 10000 12000 12 0 0
dick -- 24 0 0 6 0 0
harry -- 24 10000 12000 6 0 0
Here, we can see that the imposed limits on sally were copied to the other users, and we can see our users' current statistics: space used (blocks), soft and hard limits, even the files used (inodes) and grace periods.
In addition, users who exceed their quotas will usually not be able to run the X Window System, and if they are running X, they would likely have other problems, like launching browsers and such. When copying user quotas, remember that if you copy a user's quotas to another user that has been on the system for a while, they may be instantly put over the limit, so this is an important thing to be aware of. You should always check a user's disk usage, if they are an existing user. Another point to be aware of - if the filesystem has quotas already on, be sure to turn them off prior to executing a quotacheck, because it may damage things.
Commands:
quotacheck -- scan a filesystem for disk usage, create, check, and repair quota files quotaon ----- turn filesystem quotas on quotaoff ---- turn filesystem quotas off edquota ----- edit user quotas repquota ---- prints a report of users quota statistics quota ------- command to check quota and disk usage statistics
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/prestia.jpg)
Joey was born in Phoenix and started programming at the age fourteen on a Timex Sinclair 1000. He was driven by hopes he might be able to do something with this early model computer. He soon became proficient in the BASIC and Assembly programming languages. Joey became a programmer in 1990 and added COBOL, Fortran, and Pascal to his repertoire of programming languages. Since then has become obsessed with just about every aspect of computer science. He became enlightened and discovered RedHat Linux in 2002 when someone gave him RedHat version six. This started off a new passion centered around Linux. Currently Joey is completing his degree in Linux Networking and working on campus for the college's RedHat Academy in Arizona. He is also on the staff of the Linux Gazette as the Mirror Coordinator.
As we all know, HTTP is the protocol used for communication between Web servers and Web clients (browsers). Similarly, XMPP [1] is a protocol for communication between Instant Messaging (IM) servers and clients. Most of the popular programming languages like C, Java, Python, etc., have XMPP libraries. Ruby is my language of choice, because of the ease with which ideas can be transformed into code.
Ruby also has an XMPP library known as xmpp4r. There is also a more
abstract xmpp4r-simple
library, which was built on top of xmpp4r. Let's use
xmpp4r-simple, as our goals are relatively simple.
xmpp4r-simple can be easily installed using Rubygems, Ruby's
packaging system:
sudo gem install xmpp4r-simple
Lets write a program that:
Take a look at Program1. Replace the 'gmailusername', 'gmailpassword', and 'destination_gmailusername' in the code with with actual ones. Log in to destination_username via an Instant Messenger client, then run the program as:
$ ruby chat0.rb'Destination user' should now get a "hello" message.
Now, let's look at receiving the messages sent to us by our IM friends;
here is a program that will receive an IM message and simply bounce it
back to the sender. Log in with your username, and keep this program running
for a while. This will baffle your IM friends for sure. 
Most e-mail providers provide a service called "Auto reply" or "Holiday mail"; the idea is to send a predefined automated reply to all incoming mails. Here is a program that implements the same functionality for Instant Messenger. The program sends a predefined message in reply to every message it receives from any user. Maybe when you are busy, instead of setting status as "busy", you can simply run this program, so that it sends some appropriate reply automatically.
Now, let's try a real chat program that can be used to talk to your friends.
In this program, user1 sends a message, user2 responds, then it's user1's turn again, and so on. However, if user1 wants to send a message before user2 responds, it's not possible - this is a single-threaded program which will block while waiting for user2's response.
Using 2 separate threads for listening and sending solves this issue.
The next test is to run commands on a remote machine and get the results through Instant Messenger.
Run the program as "ruby remote_shell.rb" with user1 on a local machine. Log in as another user into an IM client from a remote machine, and send "ls" to user1 from that machine. Now, the "ls" command executes on the user1's remote machine, and the result is sent back. Commands are executed using the 'system' method, which internally uses an 'exec' system call to execute the command.
How useful would it be if you could just say "geyser ON" in your IM on your way home, which turns on the geyser at your home, so that you have warm water ready by the time you reach home? Theoretically, we can do it like this:
[ I love editing LG. Since the only 'geysers' I knew
of until this point were volcanic in origin, I had to research the Indian
meaning of the term; along the way, I found out that it is pronounced
'gee-zer' (as opposed to the American 'guy-ser' or 'guy-zer'), which leads
to much wordplay when the two cultures collide (what DO you do when a
geezer has a geyser?) In any case - in common Indian parlance, a 'geyser'
is a hot-water heater, usually turned off when one leaves home (solar ones
excluded, presumably.) Waiting for the water to warm up after you've
returned could be annoying - but using the author's ideas as noted in this
article could certainly alleviate the annoyance. On the other hand, if your
friends knew, they could create an even greater annoyance for you by having
a 'cron' job fire it up as soon as you left home - leading to a surprise
gas bill at the end of the month. Which leads us back to ancient computer
history:
"Hax0rin a
boilah"
-- Ben ]
You want to know the French equivalent for the word 'yesterday' - so you send an IM to your friend 'french-bot', and he immediately sends you back the French word for "yesterday". Wouldn't that be cool?
Here is your French-Bot
Have you talked to Eliza? If not, try it now. She is an AI chat bot. Won't it be fun if we could make Eliza talk to your IM friends, on behalf of ourselves? :)
Since we already have Ruby programs that can talk to IM servers, an interface to Eliza is the only thing we still need. Eliza's web page, shows a plain HTML form, with a text field and a submit button. The page source shows that the name of the text field is "Entry1". That's all we need! Here's the Ruby interface for Eliza:
def eliza(str)
response = Net::HTTP.post_form(URI.parse("http://www-ai.ijs.si/eliza-cgi-bin/eliza_script"),{'Entry1'=>str})
return response.body.split("</strong>\n").last.split("\n").first
end
Hats off to Ruby!!
Now, whenever a chat message arrives, we simply call this 'eliza' method, get a response string from Eliza, and send it as a reply. Here's the full Ruby code for the Eliza chat program.
'Voice chat' is a little bit of an exaggeration - we are only going to hear the received chat messages, not talk to the program. The idea is to make our IM programs read the received messages aloud, rather than us having to read it.
We will use a speech synthesis system to convert the received IM text messages to speech. Festival is an excellent Open Source speech synthesizer that has had some previous exposure here in the Linux Gazette.
These are just a few simple ideas that came to my mind as soon as I could control my Instant Messenger with my Ruby code. There can be tonnes of such interesting ideas, which may not be very useful - but fun is guaranteed. Start hacking!!!
[1] Rick Moen comments: It should be noted that XMPP, the eXtensible Messaging and Presence Protocol, is the underlying messaging/presence transport protocol of "Jabber" IM clients, and that GoogleTalk (mentioned later in this article) is an extension of XMPP that adds in VoIP functions.
(The term "Jabber" is now officially deprecated in favour of XMPP, but persists in common usage anyway.)
Other IM protocols, many of them much more common than XMPP, include Gadu-Gadu, IRC, MSN Protocol, AOL Instant Messager / ICQ's "OSCAR" protocol, AOL Instant Messager's TOC and TOC2 protocols, and Yahoo Messenger's YMSG protocol. (There are others.) XMPP is distinctive in being openly documented, stable, and modern -- along with often serving as the "glue" among otherwise incompatible services. A variety of Linux client implementations exist for sundry combinations of those IM protocols, along with a couple of good XMPP/Jabber servers and IM-gateway packages.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/unnikrishnan.jpg)
I completed my Bachelors Degree in Computer Science from Govt. Engineering College, Thrissur (Kerala, India) and am presently working at Viamentis Technologies Chennai, India, as a Software Engineer.
I presently work on Ruby on Rails. I am also interested in Ruby, Python, Hardware Interfacing Projects and Embedded systems.
More XKCD cartoons can be found here.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/2002/note.png)
I'm just this guy, you know? I'm a CNU graduate with a degree in physics. Before starting xkcd, I worked on robots at NASA's Langley Research Center in Virginia. As of June 2007 I live in Massachusetts. In my spare time I climb things, open strange doors, and go to goth clubs dressed as a frat guy so I can stand around and look terribly uncomfortable. At frat parties I do the same thing, but the other way around.
The Ecol comic strip is written for escomposlinux.org (ECOL), the web site that supports es.comp.os.linux, the Spanish USENET newsgroup for Linux. The strips are drawn in Spanish and then translated to English by the author.
These images are scaled down to minimize horizontal scrolling.
All Ecol cartoons are at tira.escomposlinux.org (Spanish), comic.escomposlinux.org (English) and http://tira.puntbarra.com/ (Catalan). The Catalan version is translated by the people who run the site; only a few episodes are currently available.These cartoons are copyright Javier Malonda. They may be copied, linked or distributed by any means. However, you may not distribute modifications. If you link to a cartoon, please notify Javier, who would appreciate hearing from you.
Talkback: Discuss this article with The Answer Gang
Mercedes-Lopez, Samuel CTR USA IMCOM [samuel.mercedeslopez at us.army.mil]
Hello Answer Guy
I was wondering if it is possible to cool a small amount of water for drinking purpose using a small cilinder of liquid fill nitrogen (by letting the water around the cilinder) is this possible and how long will the water remain cool?
Thanks
Sam
Classification: UNCLASSIFIED
Caveats: NONE
[ Thread continues here (12 messages/21.37kB) ]
umit [umit at aim4media.com]
[[[ This originally had a subject line that allegedly referred to an old LG (issue 86!) tips. It didn't bear much resemblance in the Linux-relevant portions of the thread, and even less here in Launderette. -- Kat ]]]
Selamlar, Ben Umit , Linuxgazettde tipslerde sizin isminizi gordum ve bir soru soruyum dedim ariyordum da bi neticelik. Siz nasil Debian ayarlarina yapacagini biliyormusunuz? Birde baska bir sorum olacak. Server usb dvd romu gormuyor. Nasil ayarlamam gerekir?
-- Aim4Media BV | Achter 't Veer 34 | 4191 AD | Geldermalsen | the Netherlands | T.: +31 3456 222 71 | F.: +31 3456 222 81 | MSN.:umitkaya@live.nl | WWW.: HYPERLINK "http://www.aim4media.com/"http://www.aim4media.com | @.: HYPERLINK "mailto:bram@aim4media.com"umit@aim4media.com
[ Thread continues here (16 messages/37.17kB) ]
Ben Okopnik [ben at linuxgazette.net]
On Wed, Feb 27, 2008 at 12:15:06PM -0800, Mike Orr wrote:
> On Wed, Feb 27, 2008 at 9:23 AM, Ben Okopnik <ben@linuxgazette.net> wrote:
> >
> > From what I recalled, and as confirmed by Wikipedia, Esperanto is
> > "...a language lexically predominantly Romanic... the vocabulary derives
> > primarily from the Romance languages." Seems like the most probable
> > projection of what you'd get when comparing the two languages is exactly
> > what you got.
>
> Most of the vocabulary comes from modern Romance languages. Some
> stuff does come directly from Latin ("post" being the most common),
> but it's rare enough that it's an oddity.
>
> Zamenhof was pretty random in sometimes choosing words in their
> ancient form (post = after, patro = father), sometimes with French
> idiosyncracies (preta = ready, instead of presta), and sometimes with
> German idiosyncracies (lasi = to let, instead of lati), for no
> apparent reason.
He knew that you'd try to speak it, and wanted to give you a few sleepless nights.
> I'm sure there are Russian idiosyncracies too though > I can't think of any off the top of my head except: > > okopniki = to be a vicious pirate on the high seas
"Okopniki" - is that plural, like it would be in Russian? I like the idea, mind you - although I'd have to learn to wear those cheap pirate earrings [1] and yell "Orr, matey!"
> perle okopniki = to do the same while using Perl, or in a > Perl-like manner (e.g., shouting Haiku at your enemies)
"You bloody Orr-son!" Sword-cleft head thumps deck Wind sighs in taut silence.
[1] They cost a buck-an-ear, of course.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (3 messages/4.87kB) ]
Ben Okopnik [ben at linuxgazette.net]
...it would look like this. Prepare to be scar{1,2}ed, perhaps forever.
http://blogs.sun.com/marigan/entry/how_the_vi_editor_would
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (5 messages/4.52kB) ]

![[cartoon]](misc/xkcd/content_protection.png)
![[cartoon]](misc/ecol/entiraecol-275.png)